

◆『SD-WebUI拡張機能コントロールネット&オープンポーズエディターの使い方』![]()

◆【StableDiffusion】2024年春🌸必須系👑お勧め拡張機能10選‼😊👍![]()
◆AI活用【ChatGPT🤖Stable Diffusion🎨画像編集ソフト🖼️】一撃!無料神ツール😱8倍拡大アップスケール操作テクニック‼![]()


この記事の目次
- 1 『Stable diffusion web UI』安定した拡散ウェブ・ユーザー・インターフェースとは
- 2 『Stable diffusion web UI Forge』安定した拡散ウェブ・ユーザー・インターフェース・フォージとは
- 3 『Stable diffusion web UI reForge』安定した拡散ウェブ・ユーザー・インターフェース・リフォージとは
- 4 『Stable diffusion web UI』動作環境(前提要件)推奨スペック
- 5 『Stable diffusion web UI』利用方法の種類(無料&有料)
- 6 『Stable diffusion web UI』YouTube動画:のいチャンネル
- 7 『Stable diffusion web UI』のインストール手順(導入方法)🔰
- 7.1 はじめに
- 7.2 ①『Python』のダウンロード&インストール手順(導入方法)
- 7.3 ②『Git』のダウンロード&インストール手順(導入方法)
- 7.4 ③-A『Stable diffusion web UI』(AUTOMATIC1111)ダウンロード&インストール手順(導入方法)ZIPファイル版&モデルダウンロード等
- 7.5 ③-B『Stable diffusion web UI』(AUTOMATIC1111)インストール手順(導入方法)git clone コマンドを使用する
- 7.6 『Stable diffusion web UI』インターフェースの色の変更方法・ダークを使用するメリット
- 7.7 『Stable diffusion web UI』インストール時のエラー解決方法
- 8 『Stable diffusion web UI』の日本語化 & ブラウザ翻訳機能の使い方
- 9 SD VAE・Hypernetwork・Clip skipメニューの追加方法
- 10 『Stable diffusion web UI』基本的な使い方&操作パネル(ユーザーインターフェース)概要説明
- 11 『Stable Diffusion Web UI』スプリクト「X/Y/Z Plot」の基本的な使い方&実用的な活用術
- 12 おすすめ拡張機能『LLuL』ローカル潜在アップスケーラーのインストール方法&実用的な使い方
- 13 アップスケーラー「4x-UltraSharp」の導入方法
- 14 ENSDの意味と使い方。ENSD:31137とは?ENSDの場所はどこにある?
- 15 問題解決の為の忘備録メモ
- 16 絵画のジャンル(全20種類)画風・作風・スタイル
- 16.1 ①オイルペインティング(油絵)- Oil Painting
- 16.2 ②アクリルペインティング – Acrylic Painting
- 16.3 ③水彩画 – Watercolor Painting
- 16.4 ④パステル画 – Pastel Painting
- 16.5 ⑤インク画 – Ink Painting
- 16.6 ⑥エッチング – Etching
- 16.7 ⑦リトグラフ – Lithography
- 16.8 ⑧ポートレート画 – Portrait Painting
- 16.9 ⑨静物画 – Still Life Painting
- 16.10 ⑩風景画 – Landscape Painting
- 16.11 ⑪抽象画 – Abstract Painting
- 16.12 ⑫キャンバスによるコラージュ – Canvas Collage
- 16.13 ⑬モザイクアート – Mosaic Art
- 16.14 ⑭デジタルアート – Digital Art
- 16.15 ⑮立体絵画 – Sculptural Painting
- 16.16 ⑯フレスコ画 – Fresco Painting
- 16.17 ⑰ミニチュア絵画 – Miniature Painting
- 16.18 ⑱ポップアート – Pop Art
- 16.19 ⑲レアリズム – Realism
- 16.20 ⑳モノクローム絵画 – Monochromatic Painting
- 16.21 結論:まとめ
- 17 AI画像生成ツールを活用する事で出来る事。メリット
- 18 まとめ
『Stable diffusion web UI』安定した拡散ウェブ・ユーザー・インターフェースとは
『Stable diffusion web UI Forge』安定した拡散ウェブ・ユーザー・インターフェース・フォージとは
『Stable diffusion web UI reForge』安定した拡散ウェブ・ユーザー・インターフェース・リフォージとは
『Stable diffusion web UI』動作環境(前提要件)推奨スペック
![]()
\10GB以上のNVIDIA GeForce製グラフィックボード/



『Stable diffusion web UI』利用方法の種類(無料&有料)
| AIイラスト画像生成おすすめサイト(無料&有料) | |
| Stable Diffusion Online | Stability AI社が提供する画像生成AI |
| Midjourney | 「Discord」で利用できる画像生成AI |
| SeaArt | 毎日無料のトライアル有りの画像生成AI |
| Leonardo.Ai |
毎日無料のクレジット有りの画像生成AI |
| Image Creater from Microsoft Designer | Microsoft社が提供する画像生成AI |
| Adobe Firefly | Adobe社が提供する画像生成AI 無料あり。料金:各種 プランを比較 |
| DALL-E3 | OpenAI社の画像生成AI DALLE-3はBing AIやBing Image Creatorを使用すれば無料 ChatGPTは有料プランのみDALLE-3が利用可能 |
| Canva ai | AI画像生成&動画生成。無料プラン有り ※総合デザイン系のサイト。 |
| AI PICASSO | テキストや下絵からAI画像生成できるサイト 無料プランの場合は広告有り |
| NovelAI | AIが画像や小説を生成できるサイト。有料 |
| ※ご紹介した順序はランキングではありません。 | |
✅『Stable diffusion web UI』をクラウド環境・アプリ・Webサービスで利用する場合は有料。
『Stable diffusion web UI』YouTube動画:のいチャンネル
【2分で語る】画像生成AIツール『Stable diffusion web UI』インストール手順&使い方まとめ😃サクっと解説💕YouTube 
【3分で語る】Stable diffusion web UI 拡張機能 LLuL&XYZ プロットの実用的な使い方😊画像の生成精度を更に高める方法💕YouTube
画像生成AI『Stable diffusion web UI』プロンプトの基本的な書き方【4W1H+A】&年齢と性別を制御する💕超おすすめ大文字「AND」の使い方😃YouTube
『Stable diffusion web UI』のインストール手順(導入方法)🔰
はじめに

| 【内蔵型 vs 外付け 比較】メリット&デメリット | ||
| 【内蔵型HDDのメリット】 ✅高いパフォーマンス:内蔵型HDDは通常、データ転送速度が高く、応答時間が短いため、高速なデータアクセスが可能。 ✅安全性:内蔵型HDDはケース内に収納されている為、外部からの物理的なダメージや盗難のリスクが低くなります。 ✅拡張性:内蔵型HDDはコンピュータの拡張スロットに接続される為、複数のドライブを追加する事が出来ます。 【内蔵型HDDのデメリット】 ✅取り付けと交換の難しさ:内蔵型HDDはハードウェアの取り付けや交換に専門的な知識が必要。 ✅モビリティの制約:内蔵型HDDは固定されている為、持ち運びや他のデバイスへの接続が制限されます。 |
||
| 【外付けHDDのメリット】 ✅ポータビリティ:外付け型HDDは小型で持ち運びが容易であり、複数のデバイスに接続できます。 ✅簡単な接続と交換:外付け型HDDは通常、USBなどのインターフェースを介して接続される為、接続や交換が容易です。 【外付けHDDのデメリット】 ✅性能の制約:一部の外付け型HDDは内蔵型に比べてデータ転送速度が低くなる事があります。 ✅安全性のリスク:外付け型HDDは盗難や破損のリスクが内蔵型に比べて高くなる可能性があります。 |

①『Python』のダウンロード&インストール手順(導入方法)
①『Python』バージョン3.10.9又は『Python』バージョン3.10.6「Files」の中から「Windows installer(64-bit)」を選びクリックしてダウンロード。
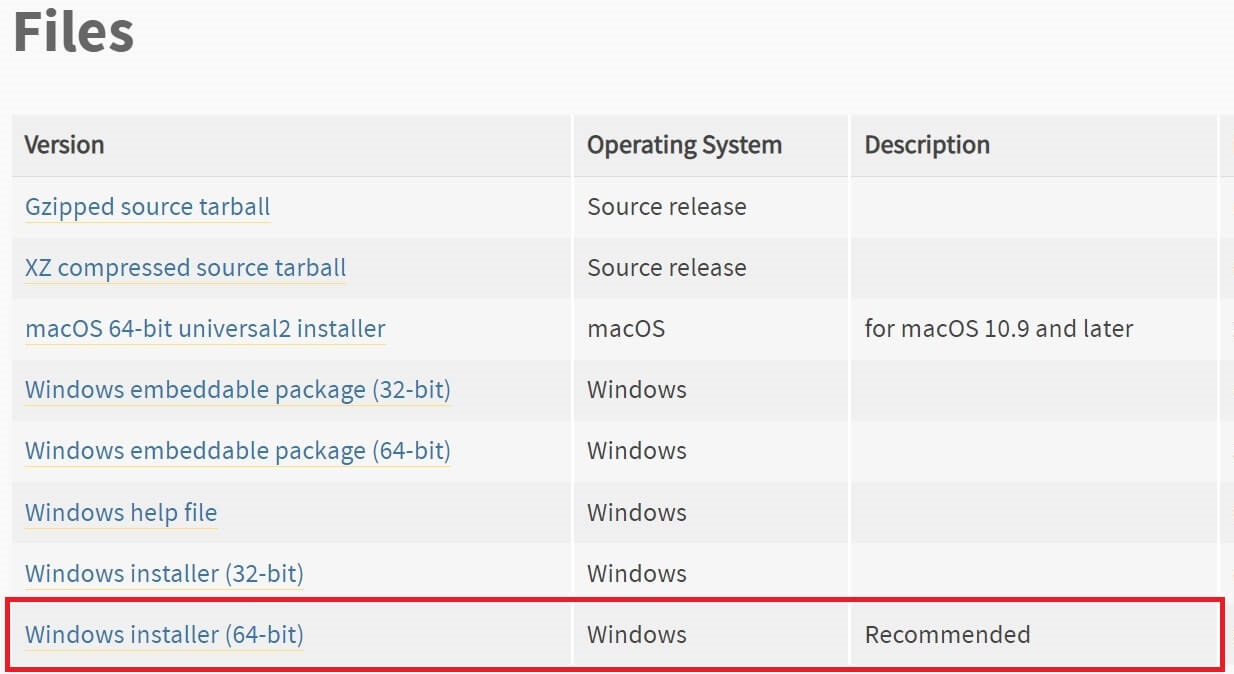
②ダウンロードした「Windows installer(64-bit)」を実行(クリック)し、任意のドライブにインストールを開始します。
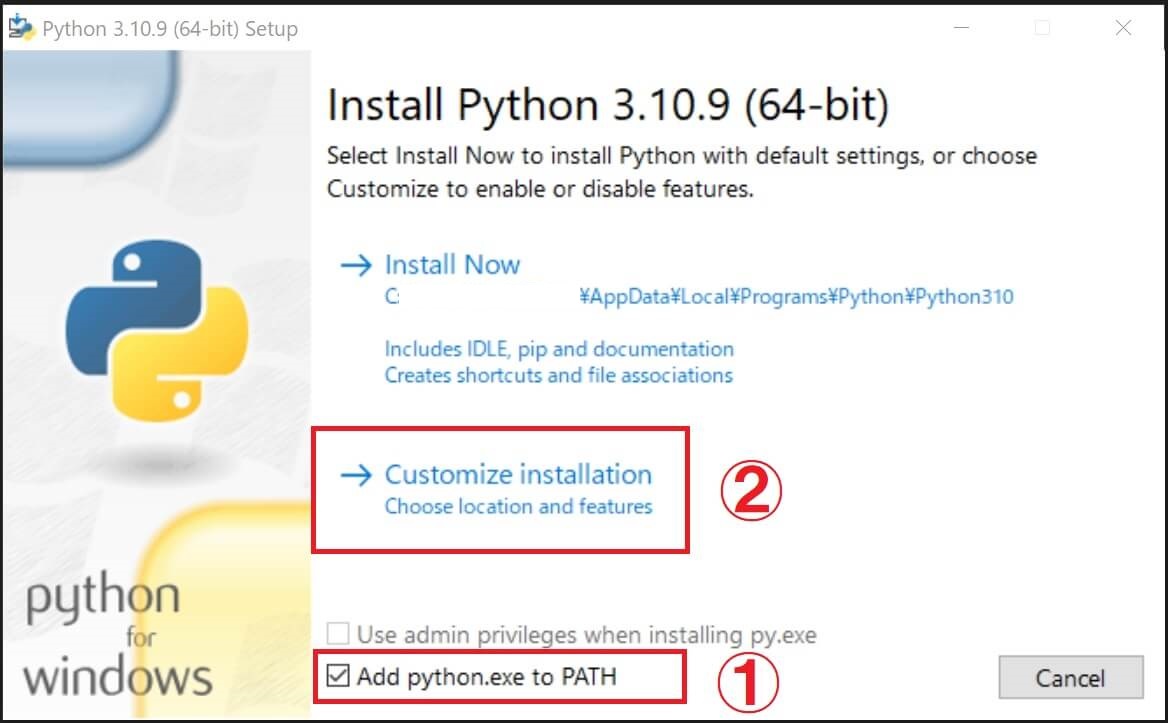
「✅Add Python.exe to PATH」にチェックを入れ、任意のドライブへ変更してインストールする為「Costomize installation」をクリックします。
③「NEXT」をクリックして次へ。
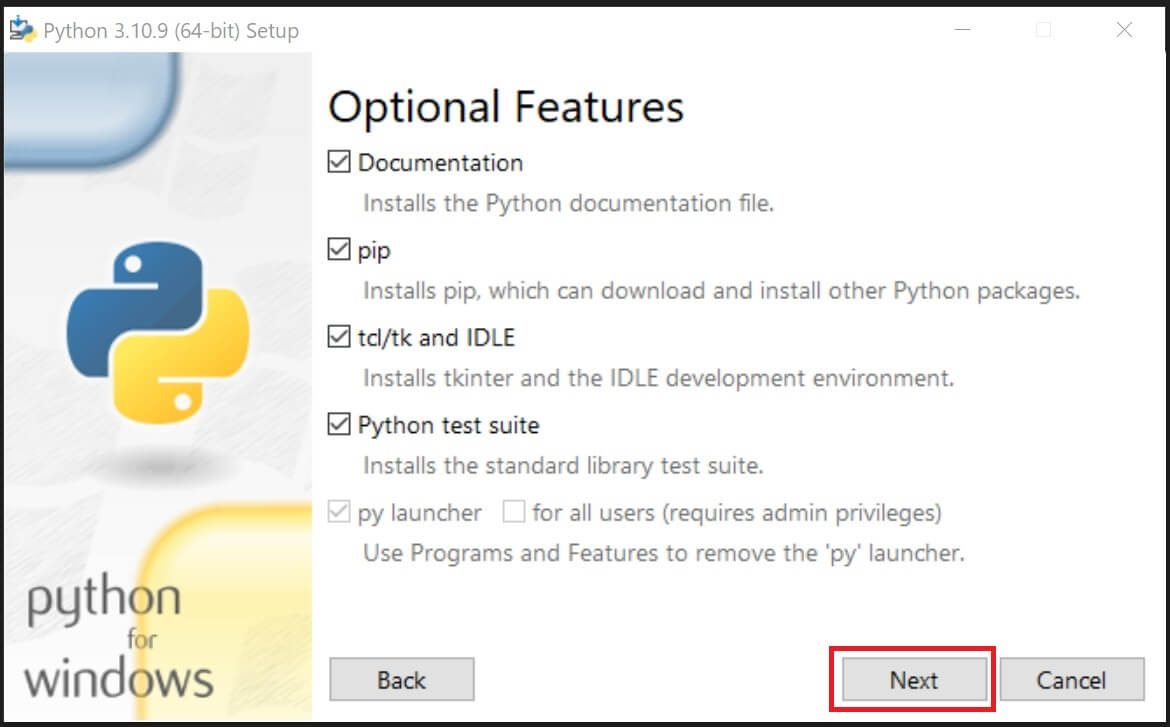
④「Customize install location」(インストール場所をカスタマイズ)内のドライブ&フォルダパスを、指定したいドライブ&フォルダ名に変更して「Install」をクリック。
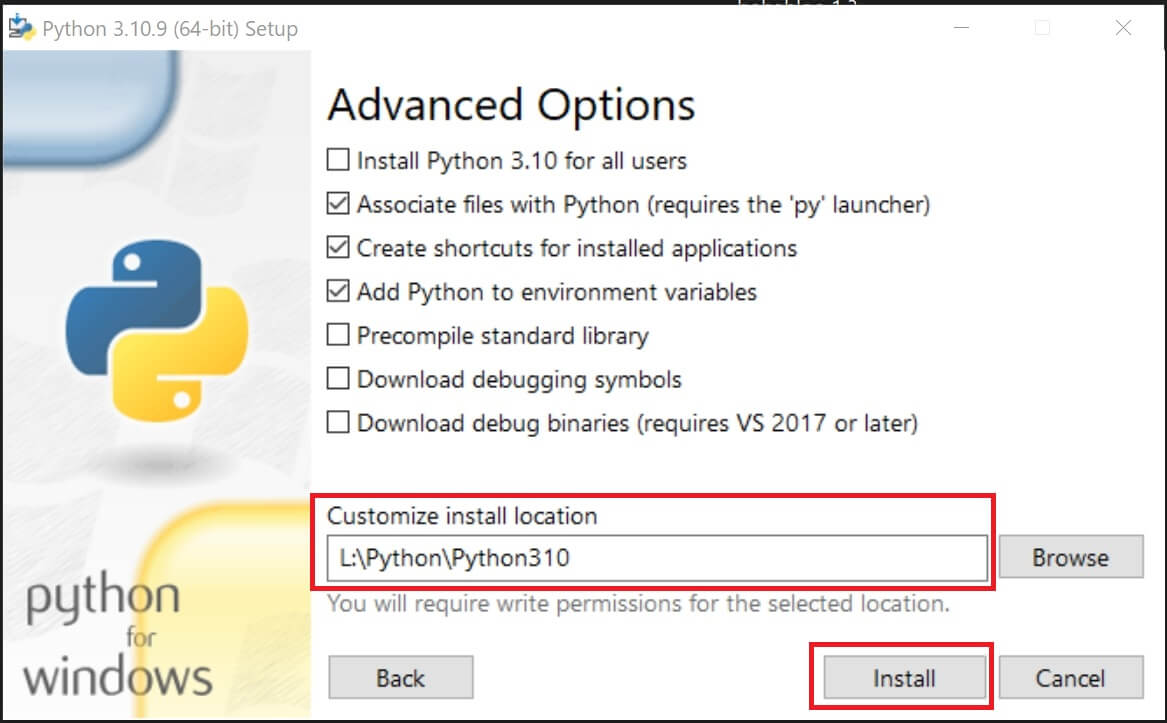
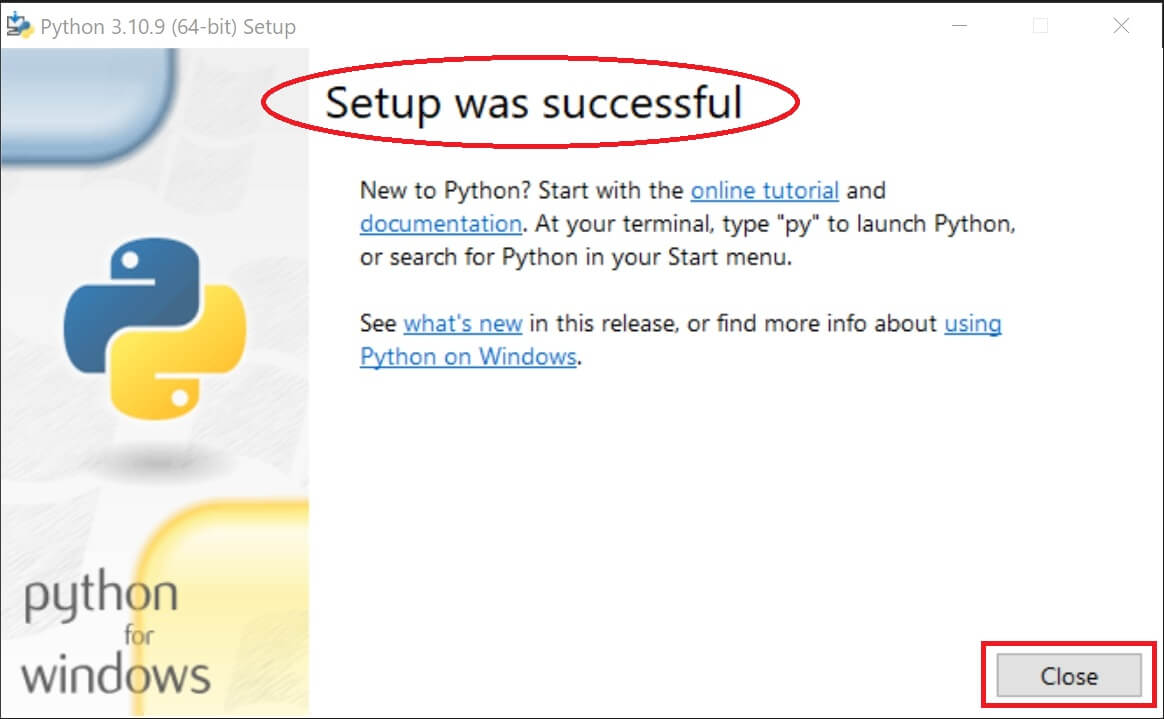
⑤「Setup was successful」(セットアップが成功)と表示されたら「Close」を押してインストール完了。
②『Git』のダウンロード&インストール手順(導入方法)
以下サイトで「Download」をクリックして『Git for Windows』最新版をダウンロードします。

 |
 |
| ※画像はクリックで拡大表示。再度クリックすると閉じます。 | |
①ダウンロードした実行ファイル(~.exe)をクリックしてインストール開始します。
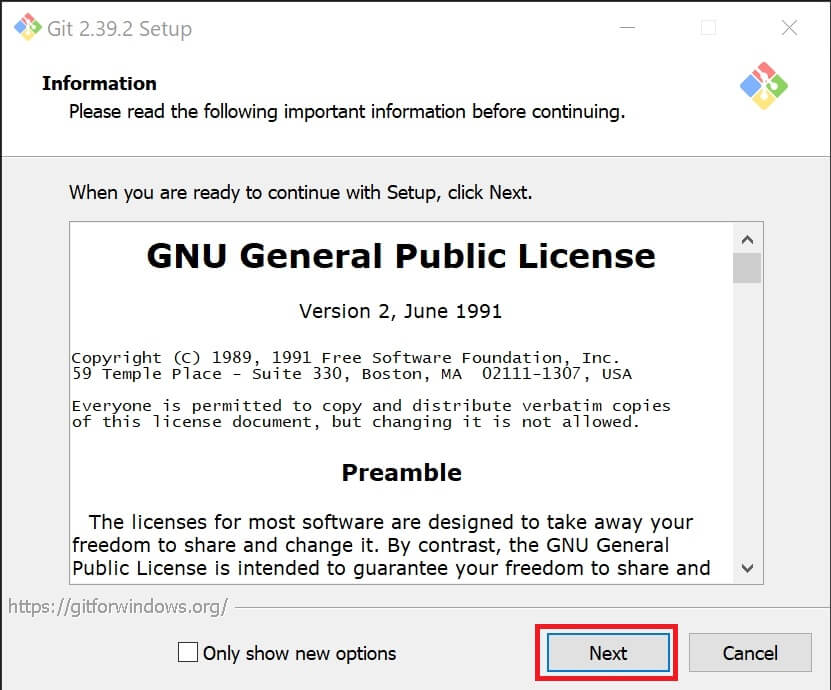
②「GNU General Public License」を読み「NEXT」をクリック。
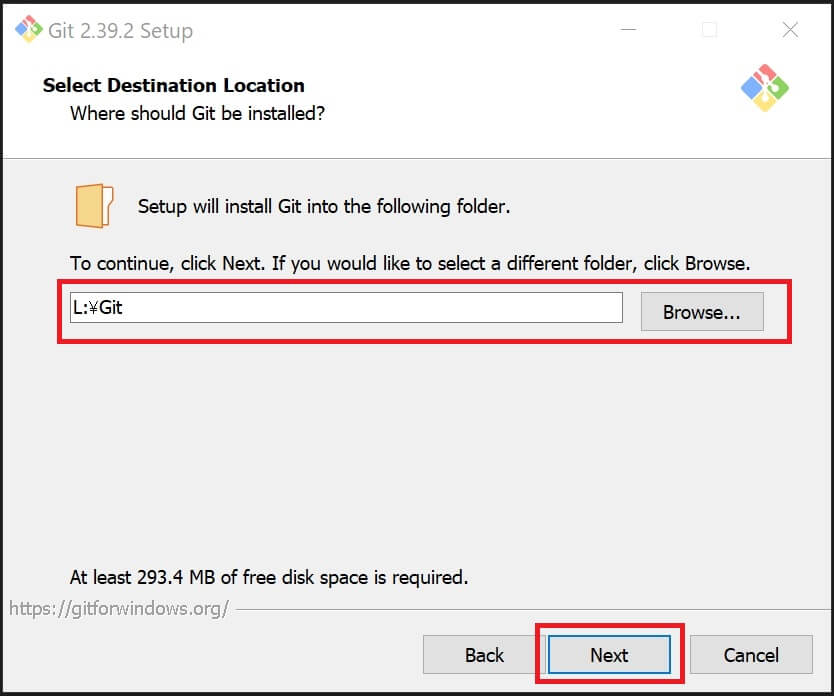
③インストール先を変更する場合「Browse」でフォルダ指定、又は、手動でドライブ&フォルダ名を入力(変更)して「NEXT」を押します。
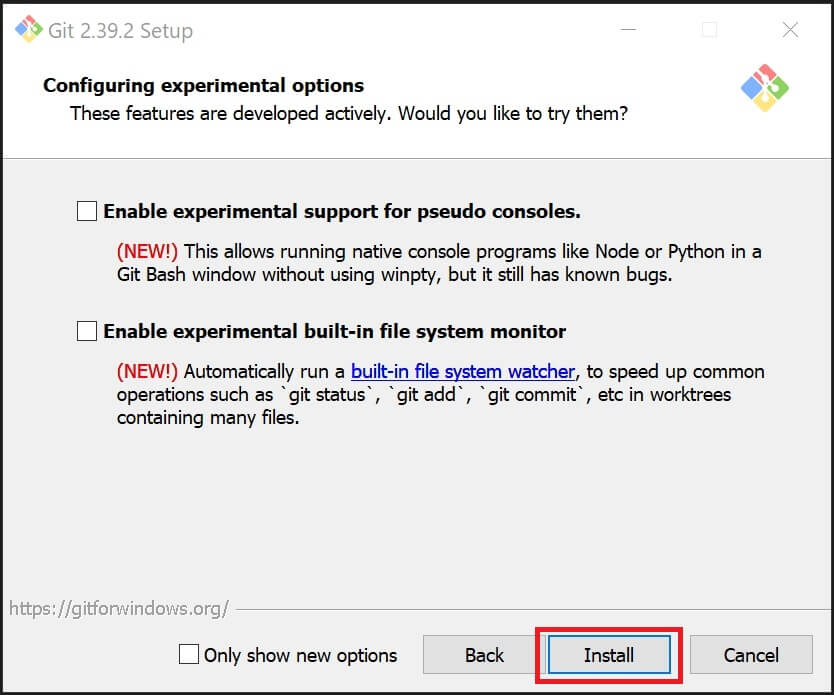
④以後、デフォルト設定のまま「NEXT」を押し進め、最後に「Install」をクリックしてインストール完了。
③-A『Stable diffusion web UI』(AUTOMATIC1111)ダウンロード&インストール手順(導入方法)ZIPファイル版&モデルダウンロード等
①以下サイト『GitHub – AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI』で「Code」タブを開き「Download ZIP」をクリックしてダウンロード。
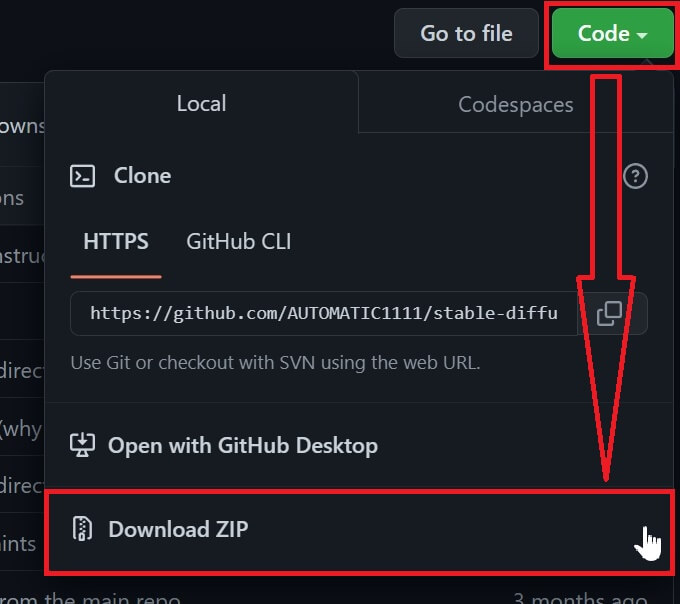
『Stable diffusion web UI』(AUTOMATIC1111)
②ダウンロードした圧縮ファイル「stable-diffusion-webui-master.zip」を解凍し、インストールしたいドライブ&フォルダへ移動(又はコピー)します。
③『Stable diffusion web UI』で画像を自動生成する為にはモデルが必要なので「Hugging Face」や「CIVITAI.com」等から、お好みのモデル・ファイルをダウンロードします。

④ダウンロードしたファイル「~.ckpt」又は「~.safetensors」を「Stable-diffusion」フォルダ内に移動(又はコピー)します。(※ファイル容量が大きいので移動推奨)
●VAEファイルが同時公開されている場合は「VAE」フォルダ内に「~vae.pt」等も配置。
⑤「stable-diffusion-webui-master」フォルダ内の「webui.bat」ファイルをクリックして実行。
⑥コマンドプロンプトが起動し、必要なファイルのインストールが開始されます。
最後に「Running on local URL: http://127.0.0.1:7860」が表示されるまで待ちます。
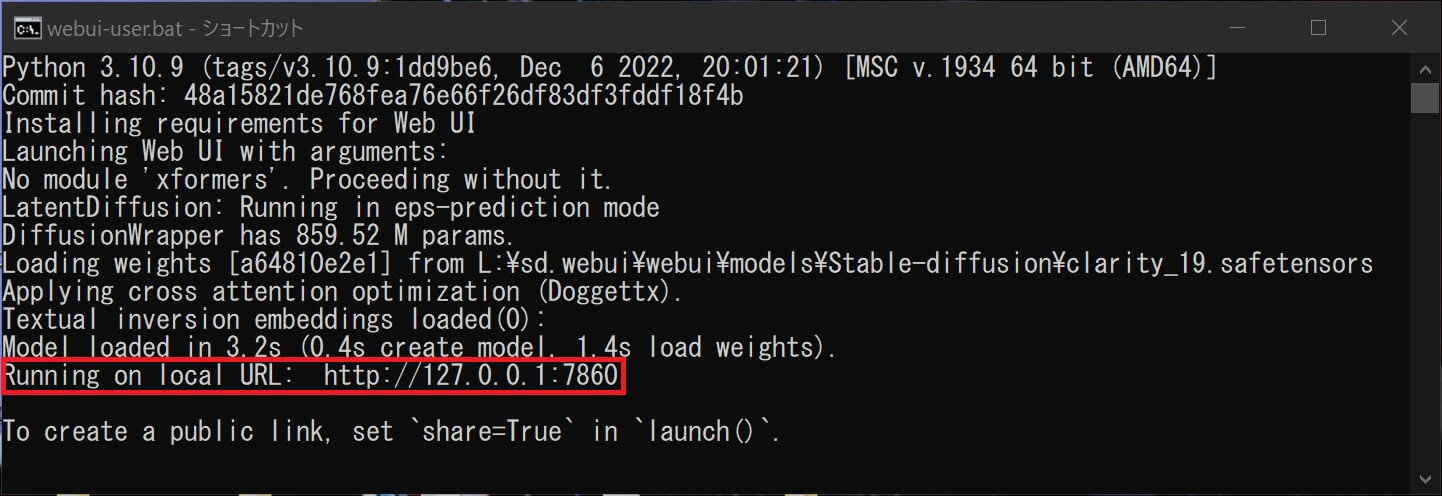
⑦正常にインストールが完了すると「Running on local URL: http://127.0.0.1:7860」(ローカルで実行中)と表示されます。

⑧お使いのブラウザ(Google Chromeなど)でアドレスバーにURL: 「http://127.0.0.1:7860」を貼付け『Stable diffusion web UI』を起動します。
⑨使い方の流れは、画面左上の所で使用したい「モデル名」を選択し、適用したいプロンプト、及びネガティブプロンプト(適用させたくない条件)を入力後【 生成 】をクリックすれば画像が自動生成されます。(詳細は後ほど解説♪)
③-B『Stable diffusion web UI』(AUTOMATIC1111)インストール手順(導入方法)git clone コマンドを使用する
メリット&デメリット
インストール手順
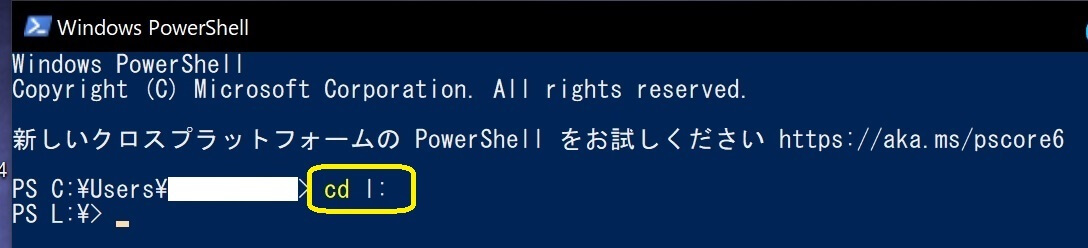
①「Windows PowerShell」を起動する。
②『Stable diffusion web UI』本体をインストールするドライブを変更する為に、以下の文字を入力した後に「エンター」キーを押します。当サイトではCドライブ以外を推奨。
③以下の文字を入力してエンターキーを押す。(コピペ可能)
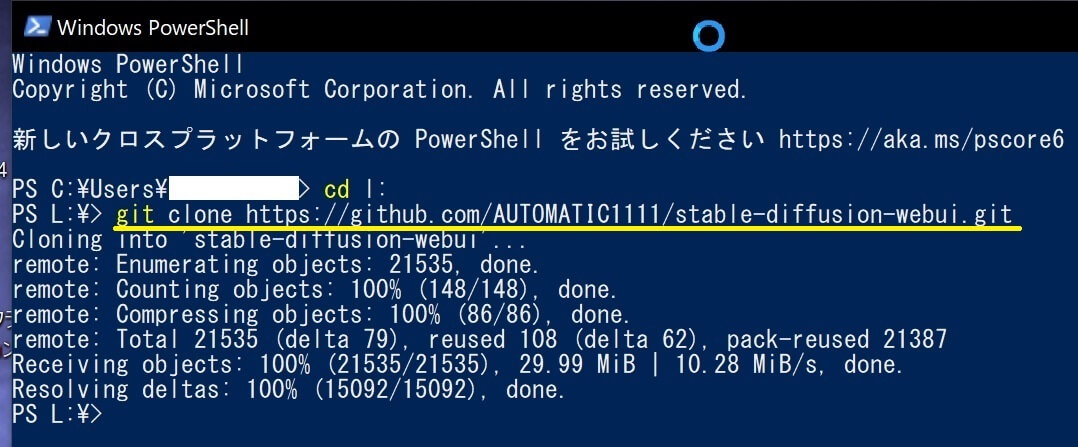
④以下の文字を入力してエンターキーを押す。(コピペ可能)
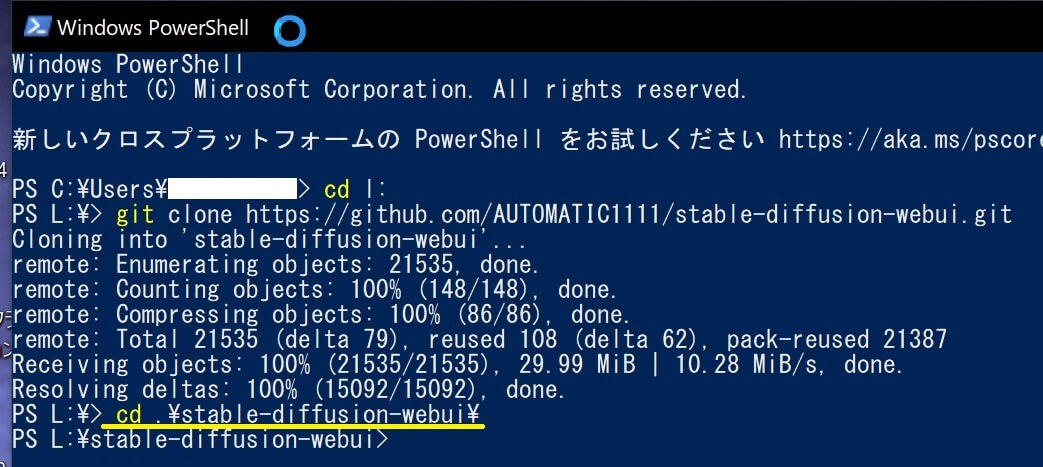
⑤以下の文字を入力してエンターキーを押す。(コピペ可能)
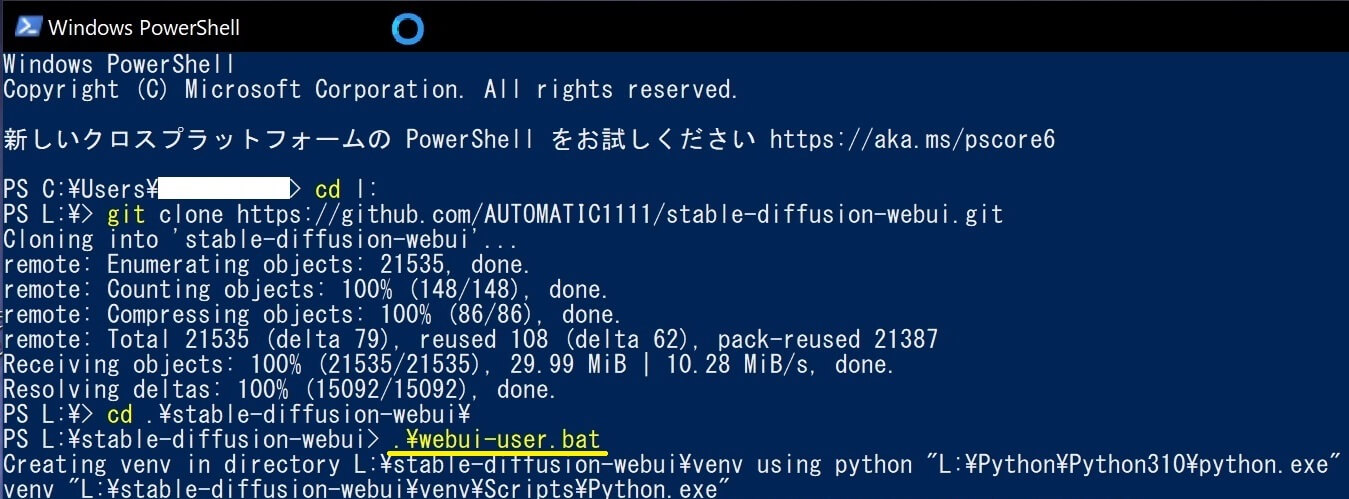
⑥以下写真のように「Running on local URL: http://127.0.0.1:7860」と表示されたらインストール完了。
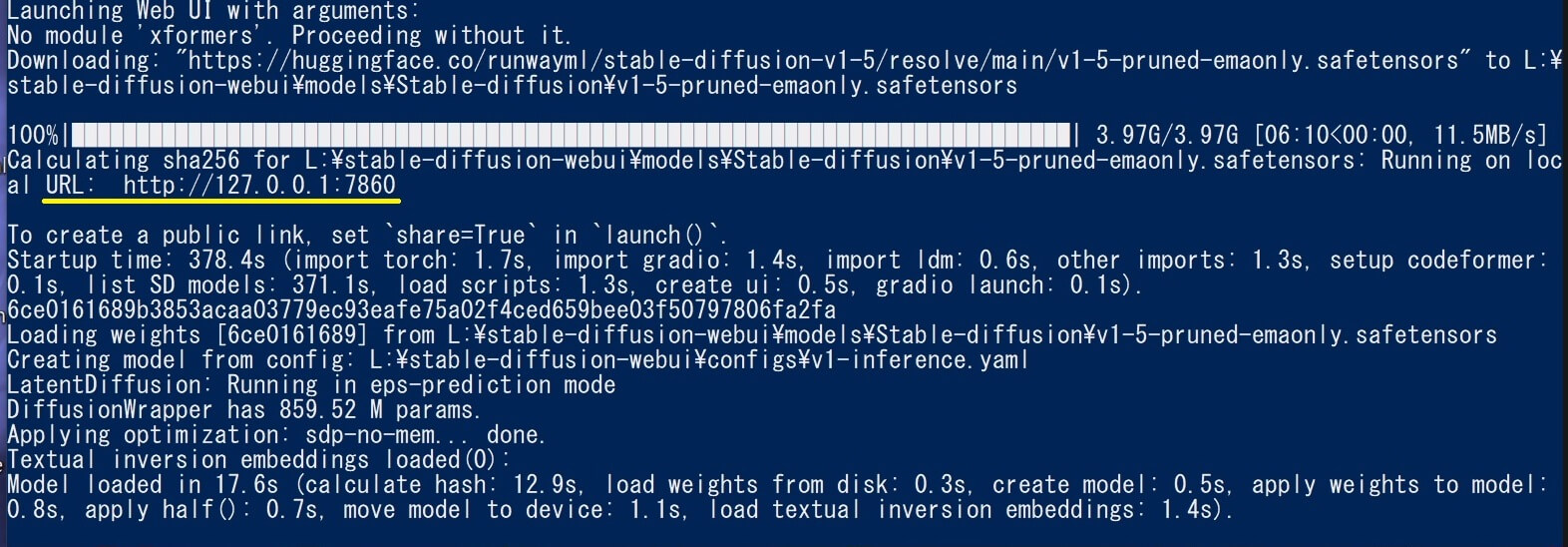
⑦ご利用中のウェブブラウザ(Chrome等)にURL(アドレス)を貼り付けて『Stable diffusion web UI』を起動します。(最新版は自動起動)
●モデルダウンロード等は、全項「ZIPファイル版インストール」の続き③に戻りご覧ください。
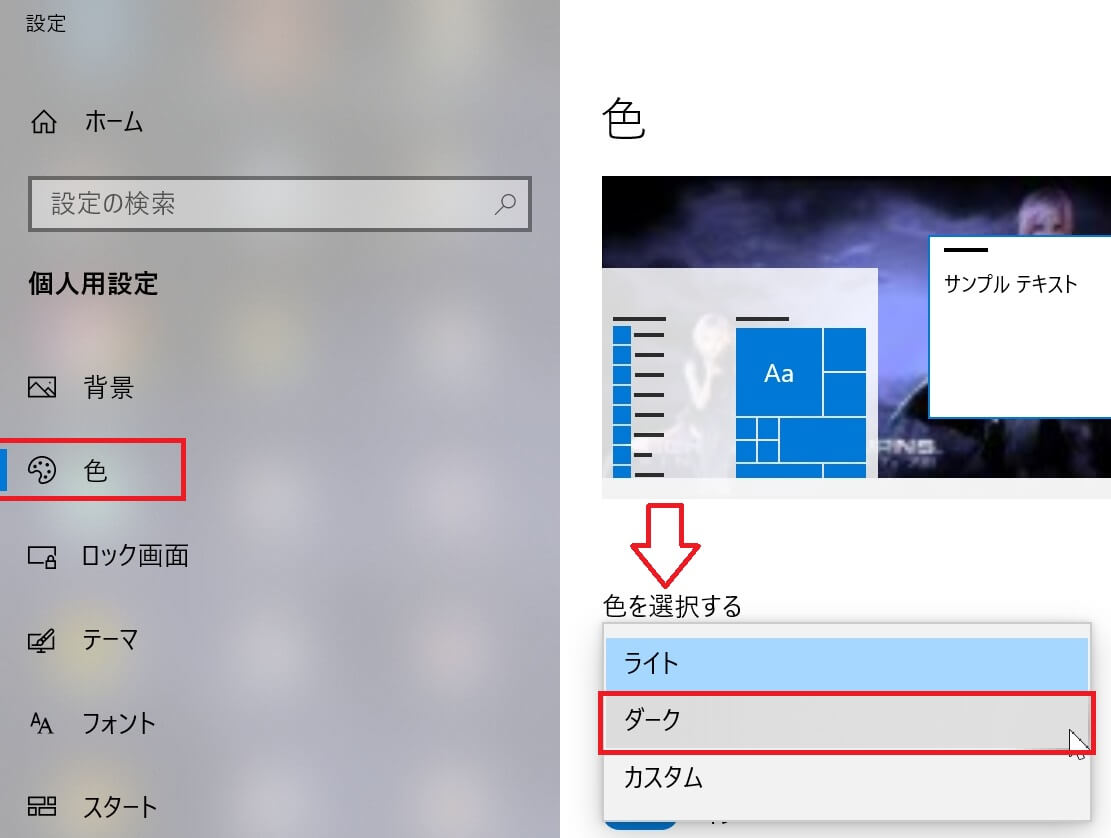
『Stable diffusion web UI』インターフェースの色の変更方法・ダークを使用するメリット
●変更方法は、WindowsPCのデスクトップ上で「右クリック」➡「個人設定」➡「色」。
➡「ライト」「ダーク」「カスタム」いずれかを選択すると色が変わります。超簡単♪
『Stable diffusion web UI』インストール時のエラー解決方法
はじめに
●まず、エラーに遭遇する一例として(古いリンクから以下サイトへ辿り着き)「webui.zip」ファイルをインストールした場合に、エラーが発生する場合が有る。↓
●もし、これ↑をインストールした方は『Stable diffusion web UI』で「Code」タブを開き「Download ZIP」をダウンロードし直す。又は「git clone」インストールをお勧めします。
インストール時のエラー解決方法
⑩『Stable diffusion web UI』内の「webui」フォルダを開き「webui-user.bat」のファイル上で右クリックしてから「編集 」を選択します。
⑪「webui-user.bat」ファイルをクリックして実行すると、コマンドプロンプトが起動し『Stable diffusion web UI』のインストールが開始されます。
⑫ランタイム・エラー「RuntimeError: Cannot add middleware after an application has started」が表示された場合、「Windows」+「R」キーを押し「cmd」と入力して、コマンドプロンプトを起動します。
⑬恐らく、最初はCドライブが表示されるので、ドライブ変更する為に「L:」(小文字でもOK)と入力し「ENTER」キーを押します。(※ドライブ名は自身の環境に合わせ読み替えて下さい。)
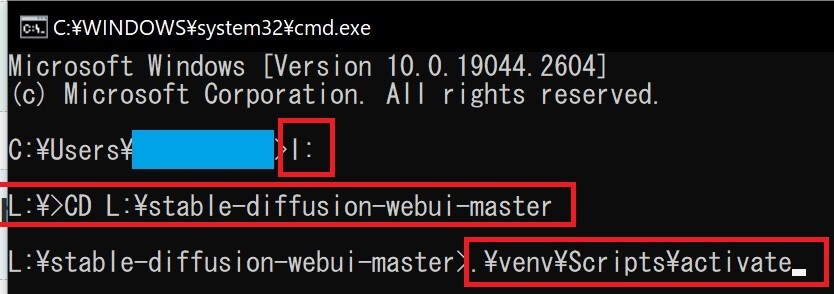
⑭次に、チェンジ・ディレクトリ(ディレクトリ変更)する為に「CD L:\stable-diffusion-webui-master」と入力後「ENTER」キーを押し『Stable diffusion web UI』フォルダを指定。
⑮「.\venv\Scripts\activate」をコピー&ペースト(貼付け)して「ENTER」キーを押します。
⑯以下画像のように「(venv)L:¥stable-diffusion-webui-master」が表示される。
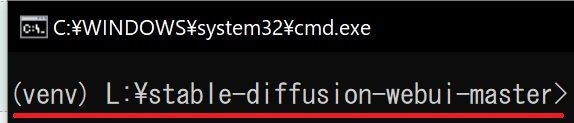
⑰「pip install fastapi==0.90.1」をコピー&ペースト(貼付け)して「ENTER」キーを押すと、pipインストールが開始されます。

⑱新しいpipバージョン利用可能(A new release of pip available)と表示されたら「python.exe -m pip install –upgrade pip」をコピペして「ENTER」キーを押しアップグレードします。
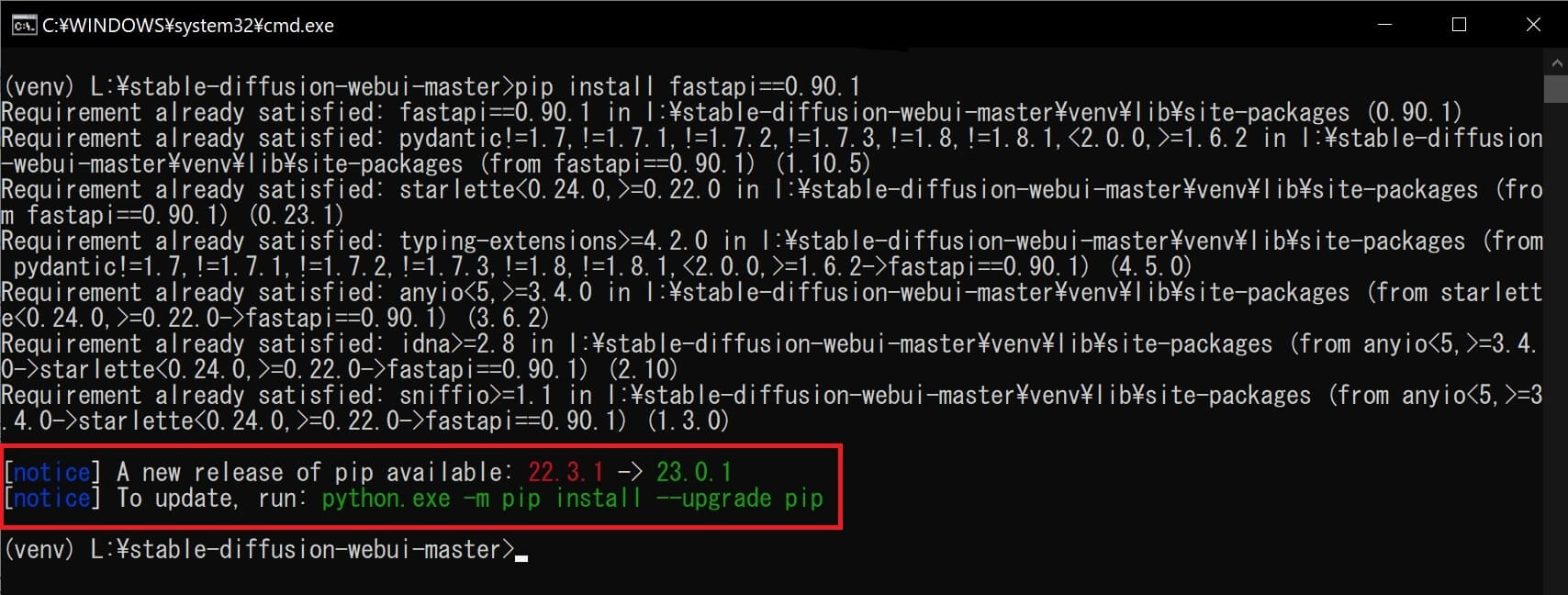
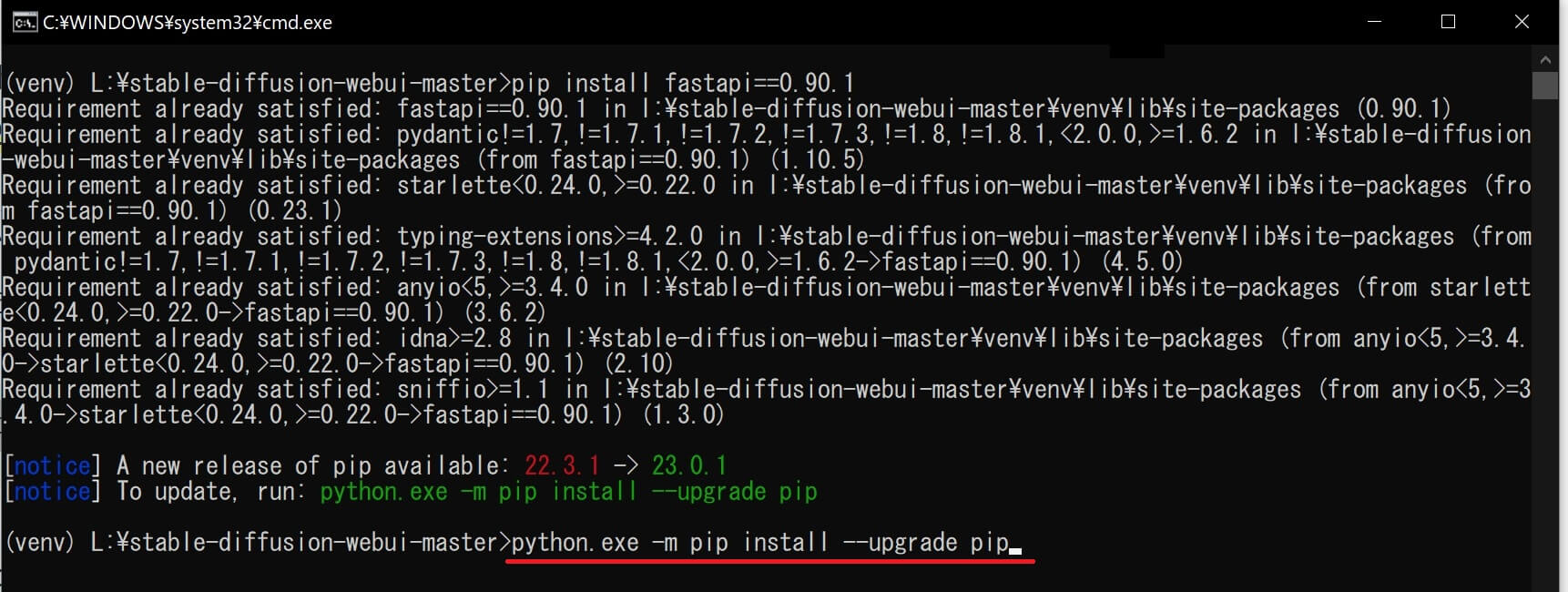
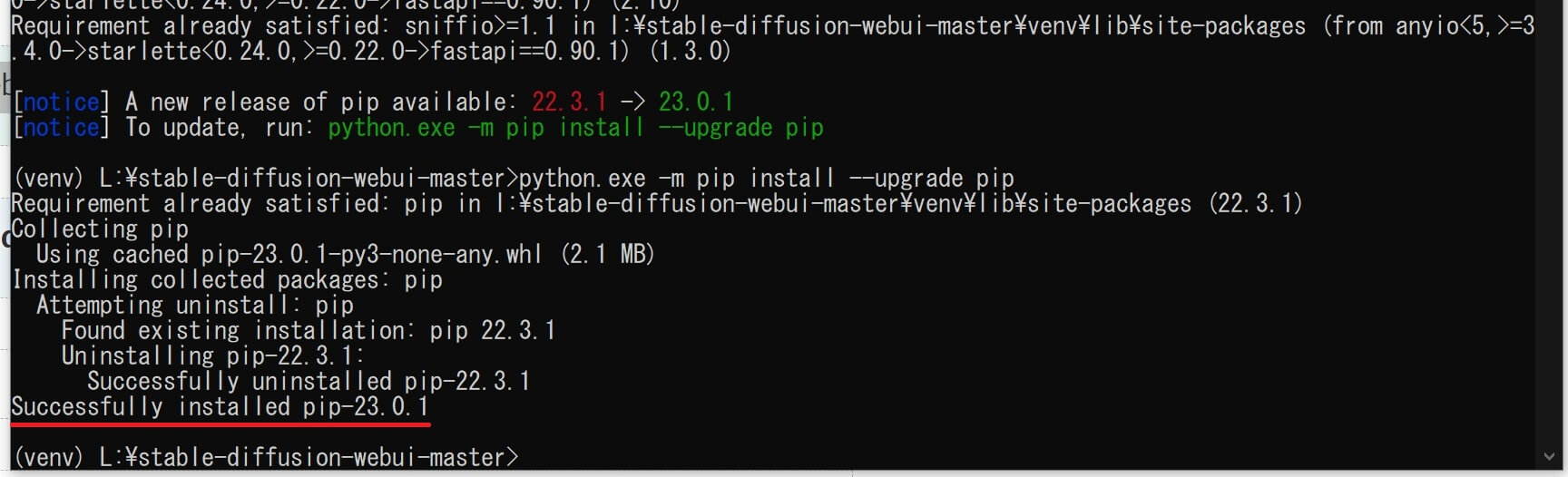
⑲「Successfully installed pip~」(pipが正常にインストールされました)と表示されたら、コマンドプロンプト画面を閉じて(pipアップグレード)作業完了。
⑳この後「webui-user.bat」ファイルをクリックすると、コマンドプロンプトが起動して『Stable diffusion web UI』のインストールが開始され、正常にインストールが完了すると「Running on local URL: http://127.0.0.1:7860」(ローカルで実行中)と表示されます。
㉑お使いのブラウザ(Google Chromeなど)でアドレスバーにURL: 「http://127.0.0.1:7860」を貼付け『Stable diffusion web UI』を起動。※最新版は自動起動
【エラー解決の為に参考にさせて頂いたサイト】↓

『Stable diffusion web UI』の日本語化 & ブラウザ翻訳機能の使い方
①「Extensions」(拡張機能)タブを開き ➡「Available」(利用可能)をクリックします。
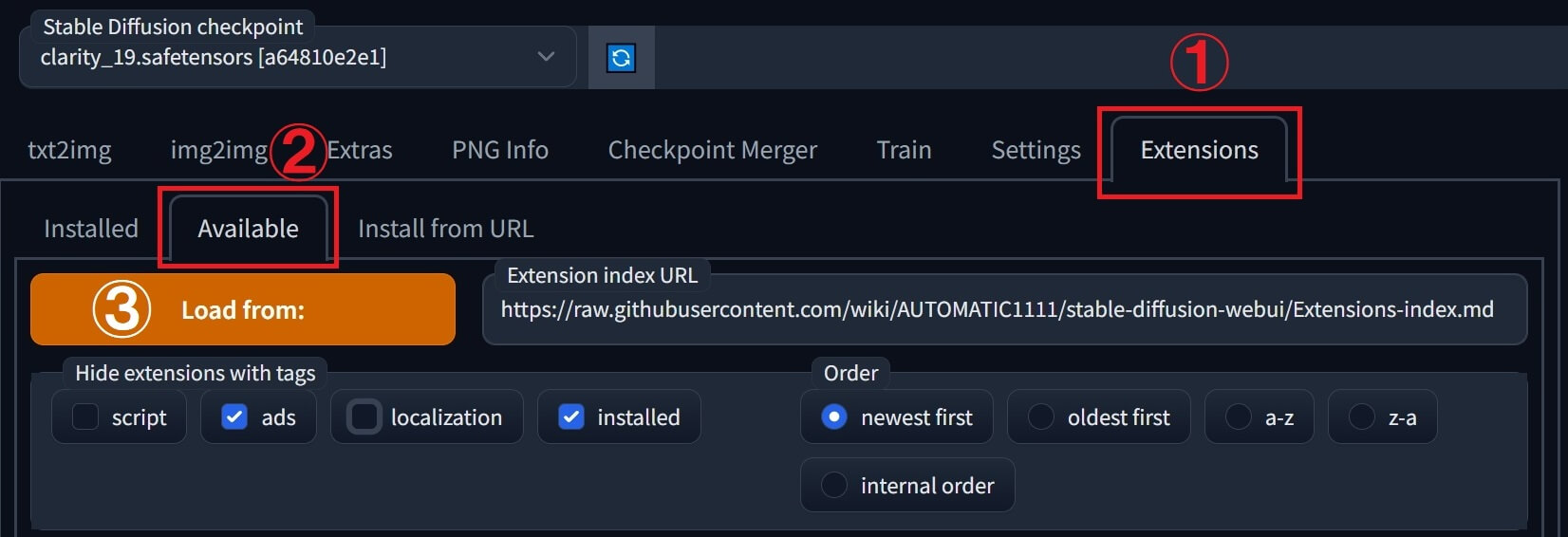
②画面の下の方。リストの中から「ja_JP Localization」を選び「Install」をクリックします。

③画面上の「Setting」(設定)タブを開き ➡ 左側の「User interface」をクリックします。

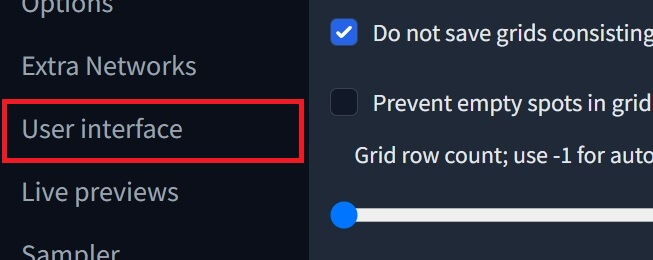
④画面の下の方「Localization」で「ja_JP」を選択します。
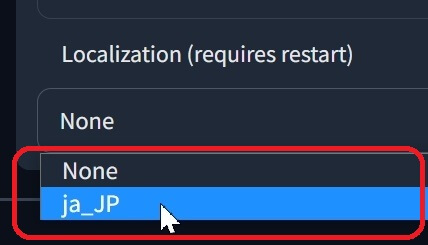
⑤最後に「Apply settings」を押し ➡「Reload UI」をクリックすると『Stable diffusion web UI』画面が再起動してUIの日本語化が完了します。

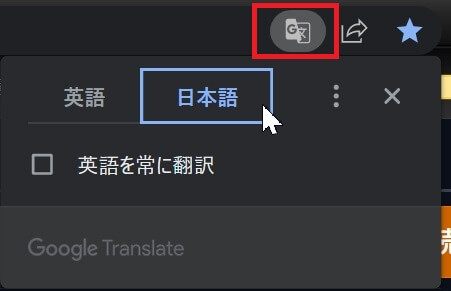
⑥更に!「ja_JP Localization」をインストールしても日本語化されない箇所は「Google Chrome」等のブラウザ翻訳機能を合わせて同時使用する事で、ほぼ全ての内容を日本語化できます。
●使い方は「Google Chrome」であれば画面右上のアドレスバー内の小さい翻訳アイコン。
➡ マウスオーバーした時に「このページを翻訳」と表示されるボタンをクリックすれば日本語化されます。
SD VAE・Hypernetwork・Clip skipメニューの追加方法
①-A 最新版の場合は『Stable diffusion web UI』の「設定」タブを開き、左側メニューの中から「ユーザーインターフェイス(User Interface)」をクリックし、[info]クイック設定の所で追加したいメニューの名前を(アルファベット半角で)入力すると候補がリストアップされるので、順に選択して下さい。
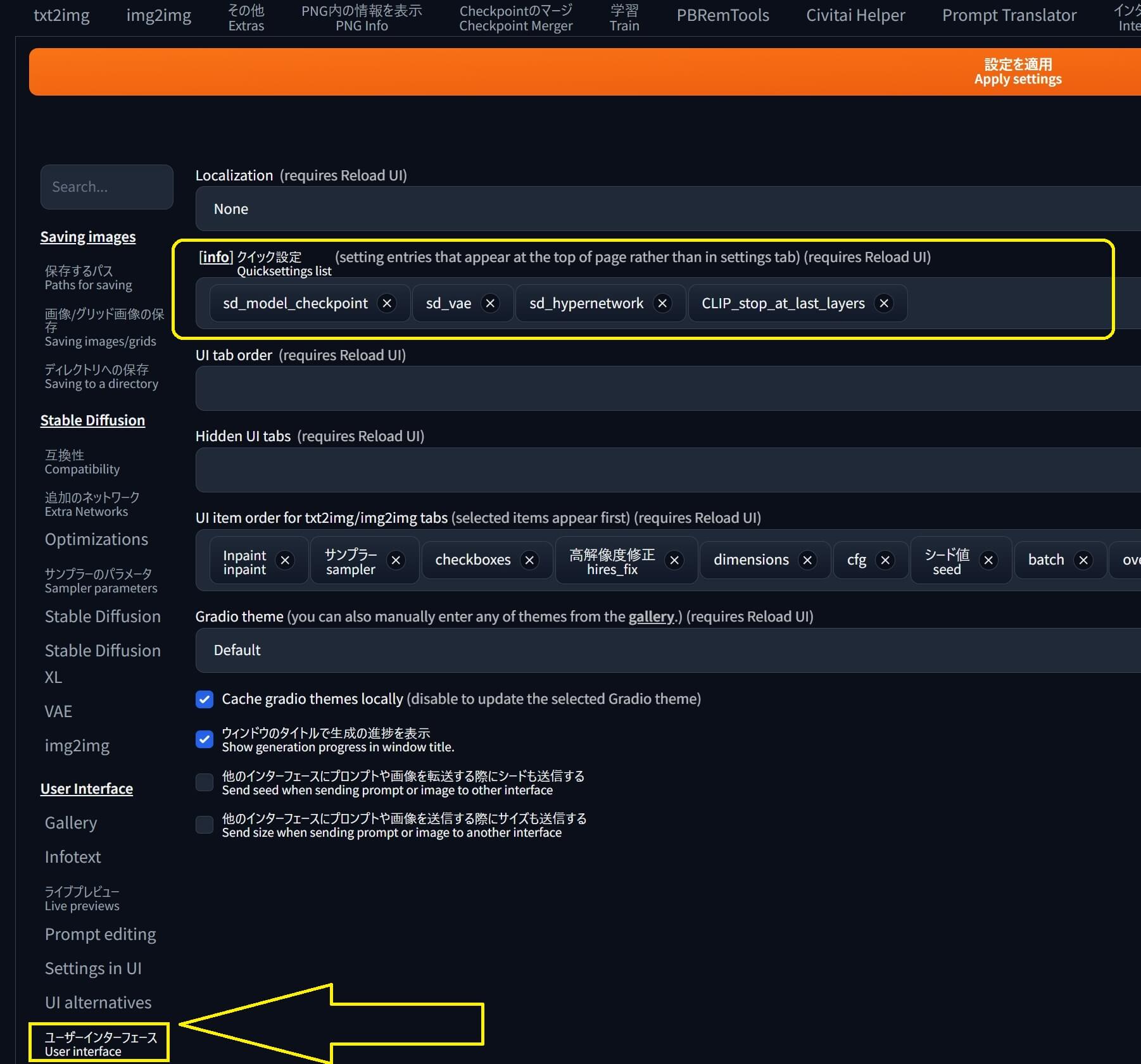
①-B 旧バージョンの場合は『Stable diffusion web UI』の「設定」タブ ➡「UI設定」 に移動し「クイック設定」の所で(以下の文章)文字をコピペして貼り付けます。

②上部の「設定を適用」を押した後に、右側の「UIの再読み込み」を押すと『Stable diffusion web UI』がリロードされて再起動します。
③『Stable diffusion web UI』の上部に、新たに「SD VAE」等が追加されます。

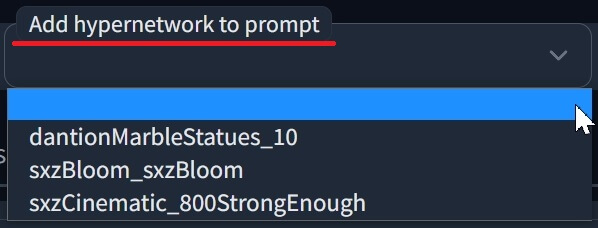
④「Add Hypernetwork to prompt」は(あらかじめインストールした)ハイパーネットワークのプリセットを選択し、プロンプトに追加できます。
⑤クリップスキップ「Clip skip」は、CLIPモデルの早期停止パラメーター。

VAEファイルダウンロード
vae-ft-mse-840000-ema-pruned.ckpt
●『Hugging Face』にある「vae-ft-mse-840000-ema-pruned.ckpt」です。

pastel-waifu-diffusion.vae.pt(Pastel Mix用)

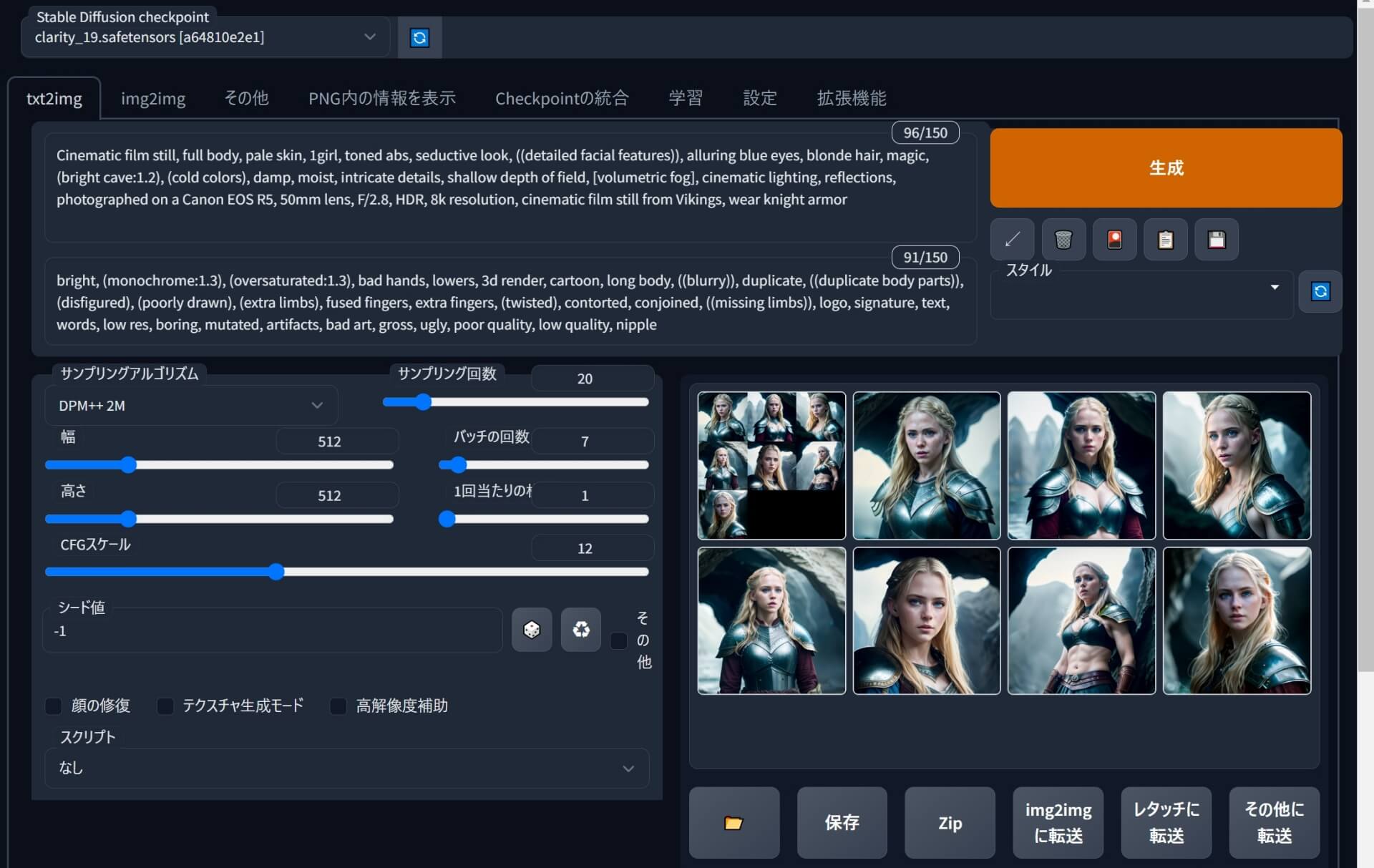
『Stable diffusion web UI』基本的な使い方&操作パネル(ユーザーインターフェース)概要説明
『Stable diffusion web UI』の基本的な使い方&操作パネル(UI)の概要を解説します。
『Stable diffusion web UI』操作パネル(ユーザーインターフェース)1/4
●画面一番左上「Stable Duffusion checkpoint」で使用するモデルを切替え出来ます。


①「txt2img」は「Text to image」の略で、文字テキストから画像を生成する時に使用します。
②「img2img」は「Image to image」の略で、画像から画像を生成する時に使用します。
③「その他」では「単一画像をアップロードして生成」や「バッチ処理」「フォルダからバッチ処理」等の操作が出来ます。
④「PNG内の情報を表示」では「画像を直接ドロップ」又はクリックするとエクスプローラーが起動し、お使いのPC内の任意の画像を指定してアップロード出来る。
⑤「Checkpointの統合」では、複数のモデルファイルを統合してマージ(merge)出来る。
⑥「学習」では「Enbedding作成」「Hypernetwork作成」「画像の前処理」「学習」の操作が出来る。
⑦「設定」では「画像ファイルの保存形式(拡張子)」や「生成画像の保存先」等々、数多くの設定が出来ます。
⑧「拡張機能」では「各種スプリクト」「主要各国のUI翻訳ファイル」等を、URLからインストール出来る。
⑨任意に指定したモデルに適用したいプロンプト(適用したい条件、採用したい内容)をテキスト入力します。(続く↓)
プロンプト&ネガティブプロンプトの基本的な書き方
生成画像の精度を高め理想的な結果を得る為の「4W1H+A」のい式
画像生成AI『Stable diffusion web UI』プロンプトの基本的な書き方【4W1H+A】&年齢と性別を制御する💕超おすすめ大文字「AND」の使い方😃YouTube ![]()
●皆様もご存知「5W1H」は、①When(いつ) ②Where(どこで) ③Who(誰が) ④What(何を) ⑤Why(なぜ)⑥How(どのように)。ですが!
| 「4W1H+A」(のい式)を具体的に「プロンプト」に使用した例 | ||
 |
 |
 |
複数条件
✅ 複数の条件を書く時は半角のカンマ(,)で区切り、半角スペースを加えてから次の条件(プロンプト)を記載すると読みやすくなる。(補足:スペースを加えなくても機能はします。)
キーワード強調の基本
✅ キーワードを強調したい場合、半角の丸カッコ( )で囲うと1.1倍、弱める場合は半角の角カッコ[ ]で囲うと0.91倍(1÷1.1=0.91)になります。
➡ 更に、キーワード(プロンプト)を強調して重み(Weight)を付ける場合、強調したい単語にコロン(:)を加え、数字を「百分率×0.01」で記載します。(1=100%、0.1=10%)
キーワードの重み(Weight)を具体的な割合(比率)で増加/減少。例①
●ボディー・パーツ(身体の部位)の重みを、具体的な割合(比率)で指定する例①。
キーワードの重み(Weight)を具体的な割合(比率)で減少。例②
●衣装・衣服・鎧などのパーツの重みを減らし弱め、具体的な割合(比率)で指定する例②。
✅ 基本的に、形容詞を含めた「英単語」や、複数の単語を組み合わせた「熟語」が利用可能。
| 『civitai.com』のモデル「clarity_19」で以下プロンプトを使い生成した例① | |
 |
【形容詞を含めた「熟語」を使用した例】 Prompt: woman with short black hair 和訳:短い黒い髪の女性 |
⑩任意に指定したモデルに適用させたくないネガティブプロンプト(適用させたくない条件、除外したい内容)をテキスト入力します。(例:モノクロ(白黒写真/白黒画像)、タトゥー/刺青)
文字リテラル「\」バックスラッシュの使い方(文字通りに理解させる)
●文字リテラル「\」バックスラッシュは、「人名」や「ゲーム/アニメタイトル」「造語」等を、「文字通り」に理解して欲しい時に使います。
●文字リテラル「\」を使う際の、定形文はこんな感じ。➡ \(○○○○\)
| 使用モデル『civitai.com』の「Clarity」。「Lora」未使用。 (この場合、顔とかはモデルに依存します。) |
|
| ①文字リテラル無し | ②文字リテラル有り |
 |
 |
| ※シード値を含め他のパラメータは同じ状態で画像生成してます。 | |
| 「雷(lightning)」をプロンプト側に追加して3D高画質化させた画像(おまけ) | |
 |
 |
プロンプト・マトリックス(prompt matrix)の書き方&スプリクトの使い方
●縦棒「|」(バーティカルバー)を使用して、複数のプロンプト(キーワード/文章)を分離し、それらを「組み合わせて画像生成」する事が出来ます。
●この場合、キーワードの組み合わせは4種類(4通り)。
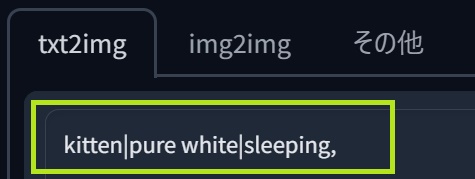 |
子猫|純白|眠っている |
 |
|
➡ その後に「生成」ボタンを押します。すると↓
| kitten|pure white|sleeping | 子猫|純白|眠っている |
 |
1つ目の「子猫」は常時固定(確定)。 ①子猫(Kitten) |
『Stable diffusion web UI』操作パネル(ユーザーインターフェース)2/4

①「生成」ボタンをクリックすると、指定したフォルダに画像が出力されます。
②「←」矢印ボタンを押すと、ユーザー・インターフェイス(UI)内のプロンプトが空欄の場合、最後に生成されたパラメーター(プロンプト&ネガティブプロンプト)等を読み取ります。
③「ゴミ箱」アイコンを押すと、現在ユーザー・インターフェイス内に書かれているパラメーター(プロンプト&ネガティブプロンプト)を削除(Delete)します。
「LORA」「Textual Inversion」「Hypernetworks」の使い方
④「🎴」花札の絵柄、坊主(ぼうず)アイコン「Show extra networks」をクリックすると、追加のネットワークを表示します。

●そして、最初「Textual Inversion」「Checkpoints」「Hypernetworks」「Lora」には「NO PREVIEW」と表示され、カードには名前しか表示されていないが、以下の方法で登録できる。↓
| プレビュー画面(なし) | プレビュー画面(置換え後) |
 |
 |
Lora・ckp等のプレビュー画面(カード/サムネイル)を登録する方法
●まず。一番楽な方法は拡張機能「Civitai Helper」を使用してモデルをダウンロードする事で「モデルファイル」に加え「サムネイル」「civitai.info」も同時に登録されます。簡単♪
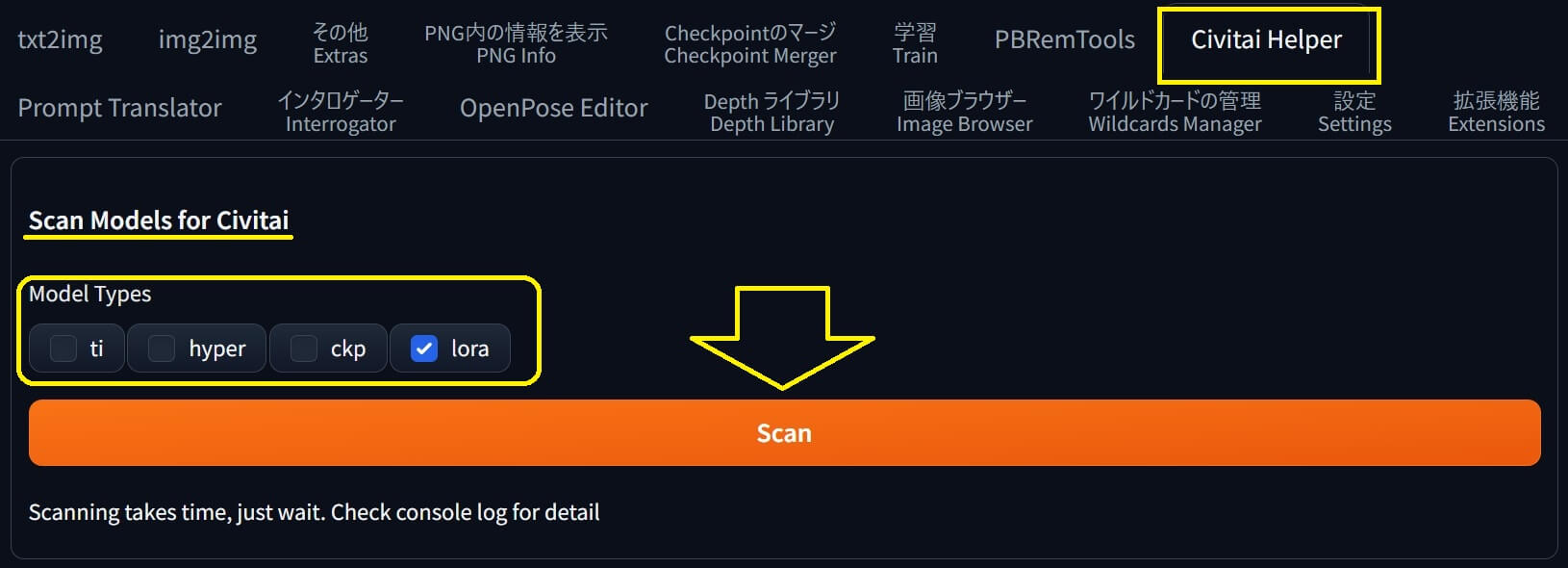
●2023年中期頃の古いSD-WEB UIをお使いの場合は、以下画像↓①の所「ギャラリー」に生成済みの画像が表示されている状態で「replace preview」をクリックすると、その画像が置き換えられ表示されます。
| ①ギャラリー | replace preview |
 |
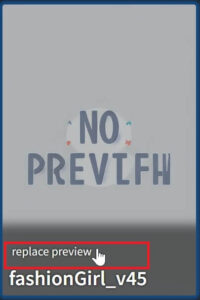 |
●基本的に、サムネ登録したい画像を「Lora」や「Checkpoints」ファイルと同じ名前に書き換え、同じ場所(フォルダ内)に収納しリロードすると反映されますが。↓
「LoRa」の基本的な使い方
●「Textual Inversion」「Hypernetworks」「Lora」は、既に任意に指定されているモデルに追加学習させて、補助的な要素を加える事が出来るオプション機能(追加学習データ)です。
「Lora:fashionGirl」を使用した例②
| LoRa:fashionGirl_v45(ロラ:ファッションガール バージョン45)を使用した例② | |
 |
モデル:「clarity_19」 Prompt: <lora:fashionGirl_v45:1> woman with short black hair 和訳:<lora:fashionGirl_v45:1> 短い黒い髪の女性 |
| ◆「Textual Inversion」「Hypernetworks」「Lora」は『Hugging Face』や『civitai.com』等から無料でダウンロード出来ます。 | |
| ◆ファイルのインストール先は『How to use models · civitai/civitai Wiki · GitHub』の説明が非常に分かりやすい。 | |
●更に!上記と同じプロンプトで「モデル」側を変更すると、追加要素「LoRa」を適用した状態で、また少し違った結果(画像)を得る事が出来ます。
同じ「Lora:fashionGirl」を使用しモデル側を変更した例③
| モデル:「clarity_19」➡ モデル「3DKX_V2」に変更 LoRa:fashionGirl_v45(ロラ:ファッションガール バージョン45)固定 プロンプトが同じでモデル側を変更した例③ |
|
 |
Prompt: <lora:fashionGirl_v45:1> woman with short black hair 和訳:<lora:fashionGirl_v45:1> 短い黒い髪の女性 |
●以上、3枚の画像を全て並べ比較すると、違いはこんな感じ♪かなり印象が違いますね💕↓
| 例① | 例② | 例③ |
|
|
|
⑤「テキスト文書」アイコンをクリックすると、現在選択中の⑦「スタイル」(「Save style」で保存されたプロンプト)の内容を呼び出し、ユーザー・インターフェイス内に表記します。
⑥「フロッピーディスク」アイコンをクリックすると、現在のユーザー・インターフェイス内に書かれているプロンプト内容を、スタイル(Style)として個別に名前を付けて保存できます。

⑦「スタイル」をクリックすると「Save style」で保存されたスタイルを読み込みます。
➡ 続けて「テキスト文書」アイコン⑤をクリックするとプロンプトを呼び出しUI内に表記します。
⑧「リサイクルアイコン」![]() のリロードボタンをクリックすると、スタイルを再読み込みします。
のリロードボタンをクリックすると、スタイルを再読み込みします。
『Stable diffusion web UI』操作パネル(ユーザーインターフェース)3/4A
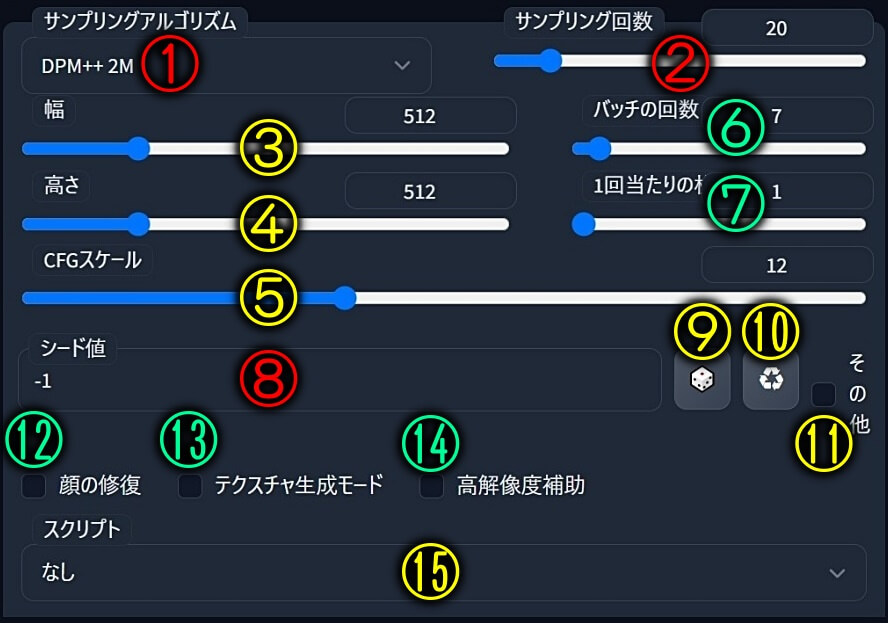
①「サンプリングアルゴリズム」では、プロンプトを読み取る際に使用する「計算方式」が違う各プリセットをユーザーが自由に選べます。
その為、同じプロンプトでも「サンプリングアルゴリズム」を変更する事で、自動生成で出力される画像(アルゴリズムで計算した答え)の結果が変わります。(つまり、式が違えば答えが変わる)
②「サンプリング回数」はアルゴリズムの読み取り回数です。
(レンジ幅:最小1~最大150)
③「幅」:生成する画像の横幅をピクセル(px)単位で指定します。
(レンジ幅:最小64~最大2048)
④「高さ」:生成する画像の高さをピクセル(px)単位で指定します。
(レンジ幅:最小64~最大2048)
⑤「CFGスケール」は、生成する画像がどの程度プロンプトに沿った画像になるか判断する為の値です。(レンジ幅:最小1~最大30)
⑥「バッチの回数」は、バッチ処理(画像生成)を何回行うか。
(レンジ幅:最小1~最大100)
⑦「1回当たりの枚数」は、1回のバッチ処理で何枚の画像を生成するか。
(レンジ幅:最小1~最大8)
⑧「シード値」は乱数発生器の出力を決定する値。(Seed=種子、種、実という意味)
同じパラメータとシードで画像を作成すれば、同じ結果が得られます。その逆もしかり。
⑨「サイコロ」ボタンを押し「シード値」をマイナス1(-1)に設定すると、毎回新しい乱数が使用され、毎回違った結果が得られます。なので↓
⑩三角の「リユース(Reuse)」再利用アイコンをクリックすると、最後(直前)に利用したシード値を再利用して固定します。
⑪「その他」をクリックすると隠されているメニューが開き「Valiation seed」「Valiation strength」「Resize seed from width」「Resize seed from height」等を設定できる。
⑫「顔の修復」にチェックを入れると、顔を修復します。まんま♪
⑬「テクスチャ生成モード」にチェックを入れると、タイルとして扱える画像を生成します。
つまり、同じ画像を縦横に並べタイル張りすると、繋ぎ目が完全に分からない絵(画像)になる。
⑭「高解像度補助」にチェックを入れると、隠されていたメニューが表示され「アップスケーラー」「高解像度の回数」「ノイズ除去強度」「アップスケール」「幅変更」「高さ変更」が出来る。
⑮「スプリクト」は3種類。特殊なプロンプトの記載方法で、便利機能が使えるようになります。
『Stable diffusion web UI』操作パネル(ユーザーインターフェース)3/4B
手順⑭で「高解像度補助」に ✅チェックを入れた時に表示される、メニューの概要解説です。
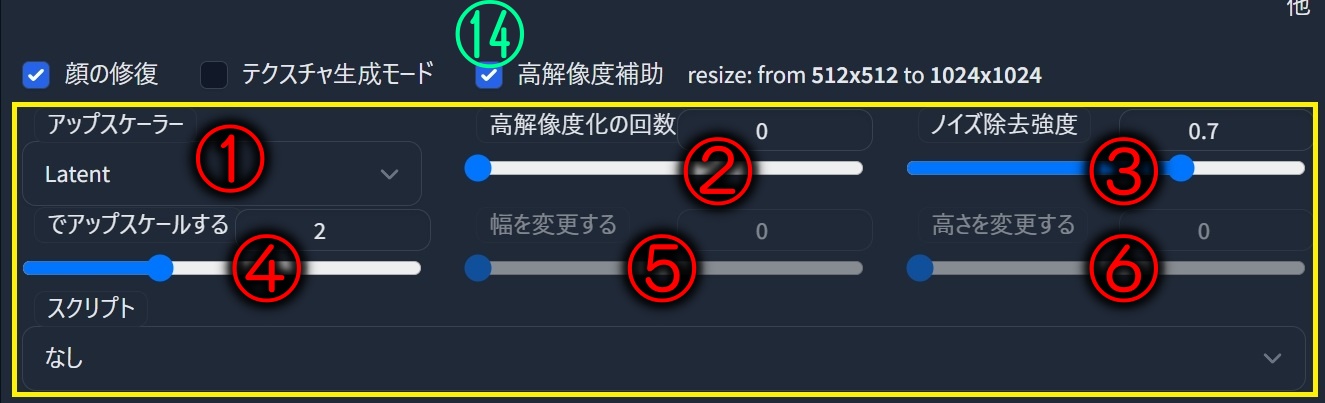
①「アップスケーラー」で以下の、各種プリセットが選べます。
| アップスケーラー・プリセットリスト(全16種)※なしを含む | |
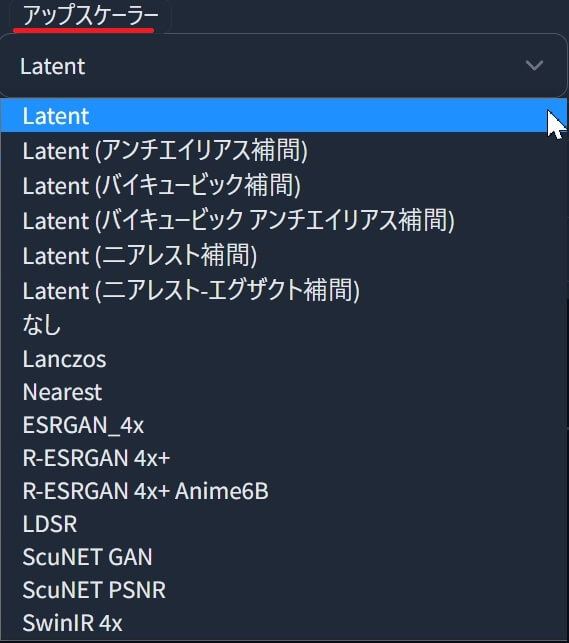 |
Latent Lanczos、Nearest、ESRGAN_4x、 LDSR、ScuNET GAN |
②「高解像度化の回数」は、拡大縮小図のサンプリング回数。
③「ノイズ除去強度」はアルゴリズムが画像の内容をどの程度参考にするか決定します。
1.0未満の値では、スライダーで指定した「サンプリングステップ数」よりも少ないステップ数で処理が行われます。
④画像の幅と高さを、何倍でアップスケールするか。(デフォルト値:2)
◆既に生成済みの「お気に入り画像」のプロンプトを確認する方法は以下記事内で公開中♪
⑤画像のサイズをこの幅に変更します。
⑥画像のサイズをこの高さに変更します。
『Stable diffusion web UI』操作パネル(ユーザーインターフェース)4/4

①画像生成中のプレビュー画面、及び、生成後の画像(ギャラリー)が表示されます。
●画像生成中に表示される上部の進行バーには「%」と「ETA(Estimated Time of Arrival):到着予定時間」が表示される。
②「フォルダアイコン」をクリックすると、以下画像↓⑦「設定」➡「保存する場所」で設定されている画像出力ディレクトリのフォルダが開きます。
③「保存」ボタンを押すと、画像をフォルダ(デフォルト:log/images)に保存。
加えて、生成パラメータをCSVファイルに書き出します。
④「ZIP」ボタンをクリックすると、生成された画像を圧縮しZIPファイルでダウンロードできる。
加えて、圧縮されていないPNG画像も、同時にダウンロード出来ます。
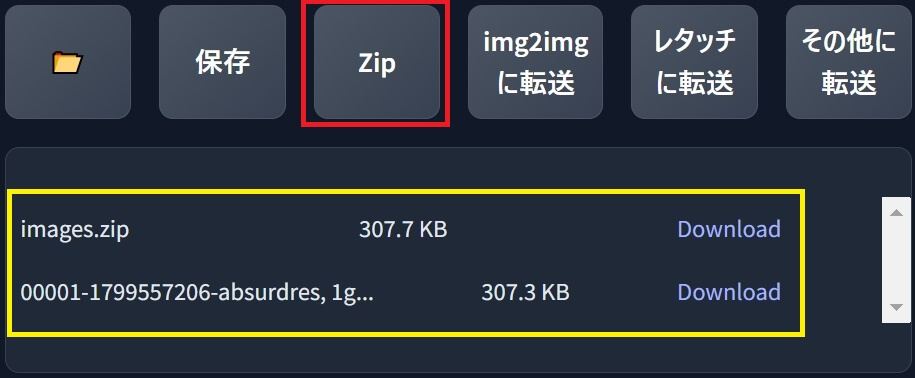
⑤「img2imgに転送」ボタンを押すと、生成した画像を「img2img」へ転送します。
⑥「レタッチに転送」ボタンを押すと、生成した画像を「レタッチ(Inpaint)」へ転送します。
⑦「その他に転送」ボタンを押すと、生成した画像を「その他」へ転送します。
以上が『Stable diffusion web UI』の基本的な使い方&操作パネル(UI)の概要解説です。
『Stable Diffusion Web UI』スプリクト「X/Y/Z Plot」の基本的な使い方&実用的な活用術
【3分で語る】Stable diffusion web UI 拡張機能 LLuL&XYZ プロットの実用的な使い方😊画像の生成精度を更に高める方法💕YouTube
スプリクト「X/Y/Z Plot」の基本的な使い方
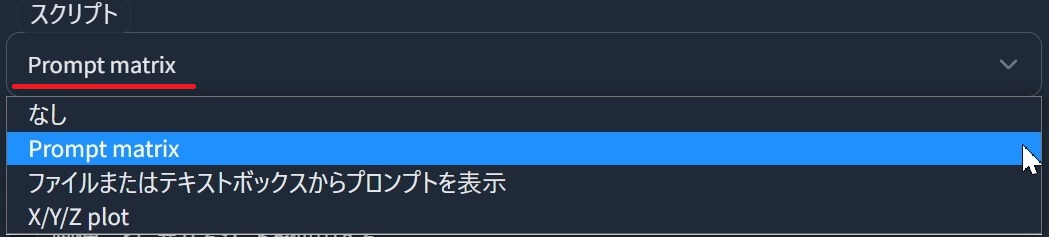
①まず、スプリクトのプリセットの中から「X/Y/Z Plot」を選択すると、隠されていたメニューが下部に出現します。
| スプリクトのプリセット選択メニュー | スプリクト「X/Y/Z Plot」 |
|
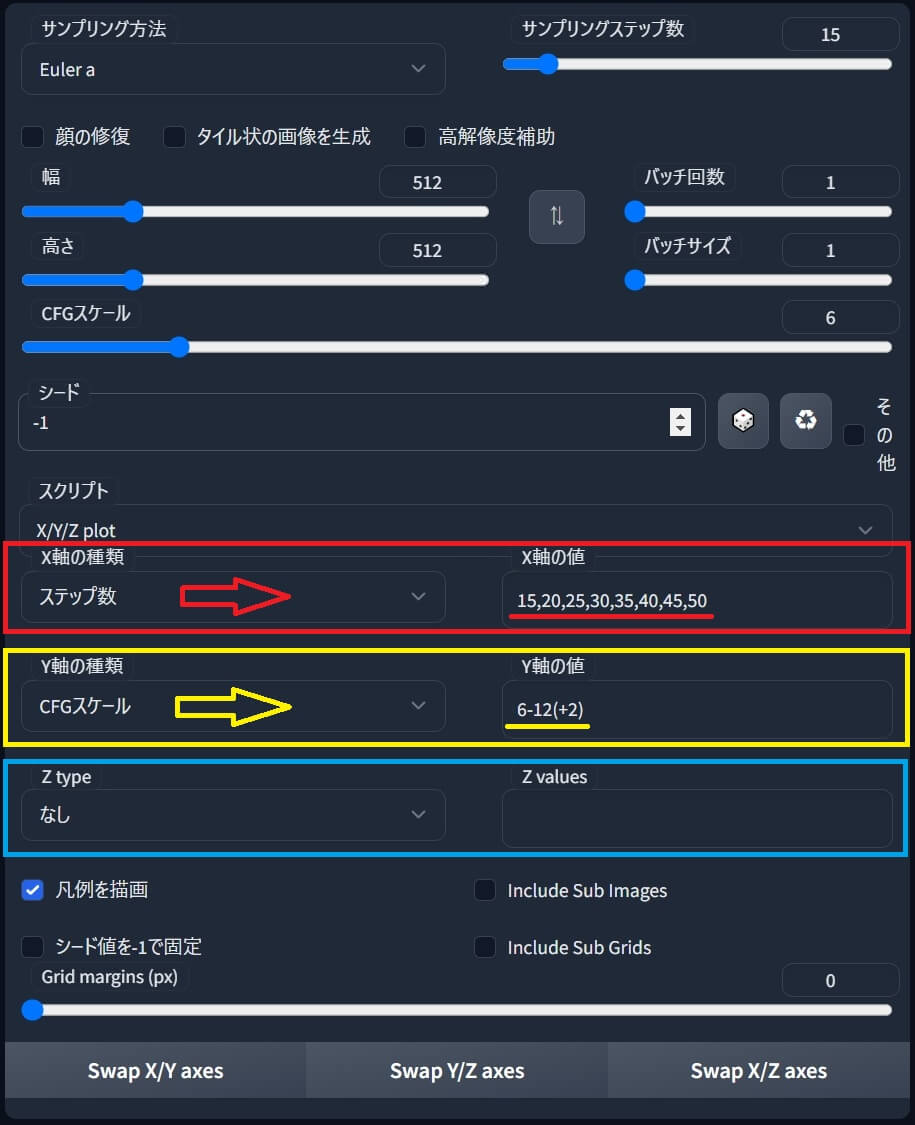 |

●「ステップ数」の場合、画像生成したい種類のステップ数を、それぞれカンマ区切り「,」で入力します。
●「CFGスケール」の場合は「最初の値」から「最後の値」の中間にハイフン「-」を追加し、いくつ刻みで「値」を増加させるかをプラス「+」と数字の組合せで指定します。
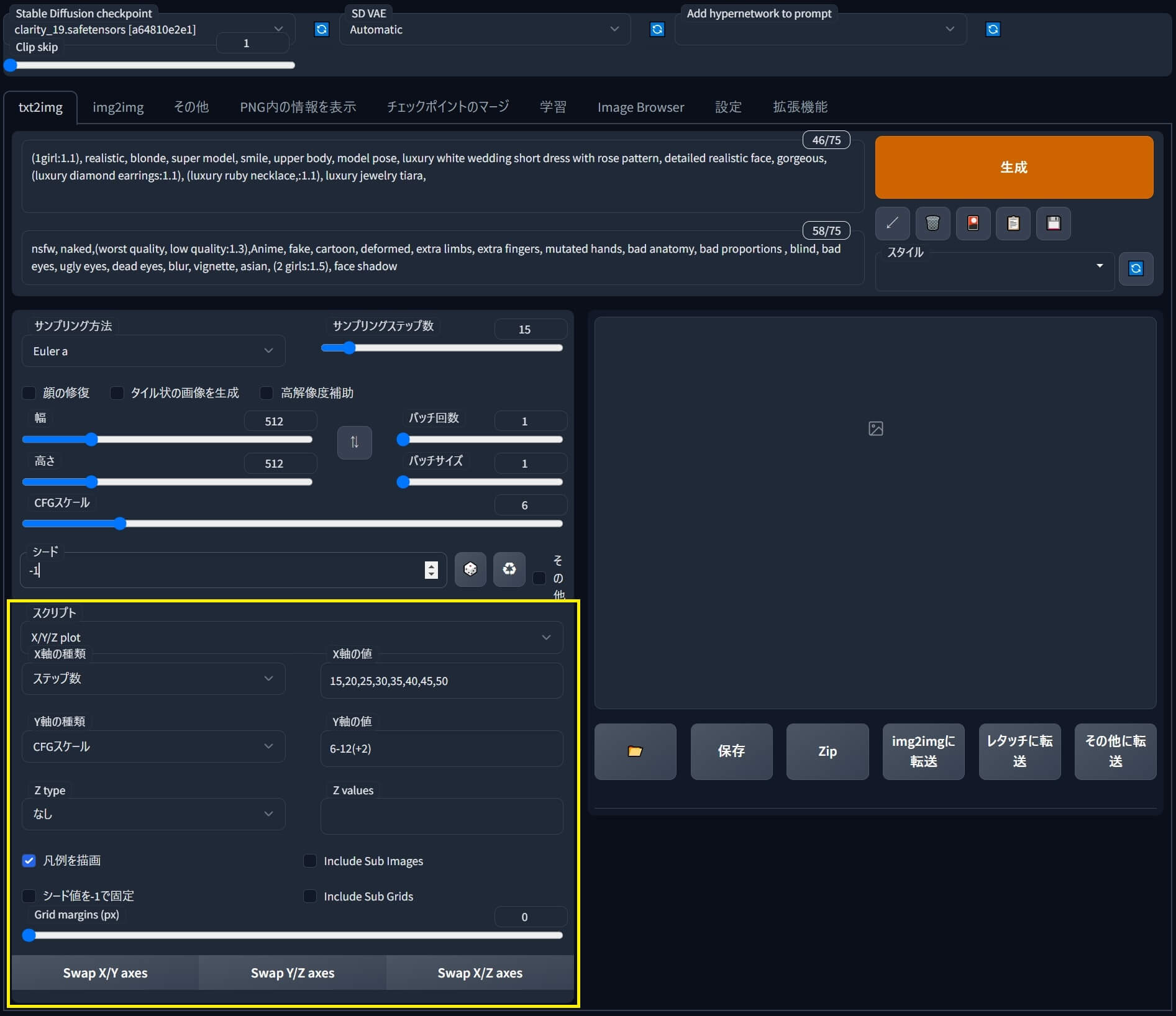
②その後「生成」ボタンをクリックすると「ステップ数」全8種×「CFGスケール」4種類で ➡ 合計32枚の画像が出力される。と同時に「グリッド画像」も指定フォルダへ保存されます。
 |
| 画像はクリックで拡大💕 再度クリックで閉じます♪ |
生成画像の精度を高め理想的な結果を得る為のスプリクト「X/Y/Z Plot」活用術
①出力された「グリッド画像」を見比べ中から「お気に入り画像」を一つ選びます。
②本解説では、★マークの所「ステップ数45」「CFGスケール10」の画像を「お気に入り画像」として選んだので、各値を変更した後に✅「高解像度補助」にチェックを入れ再生成します。
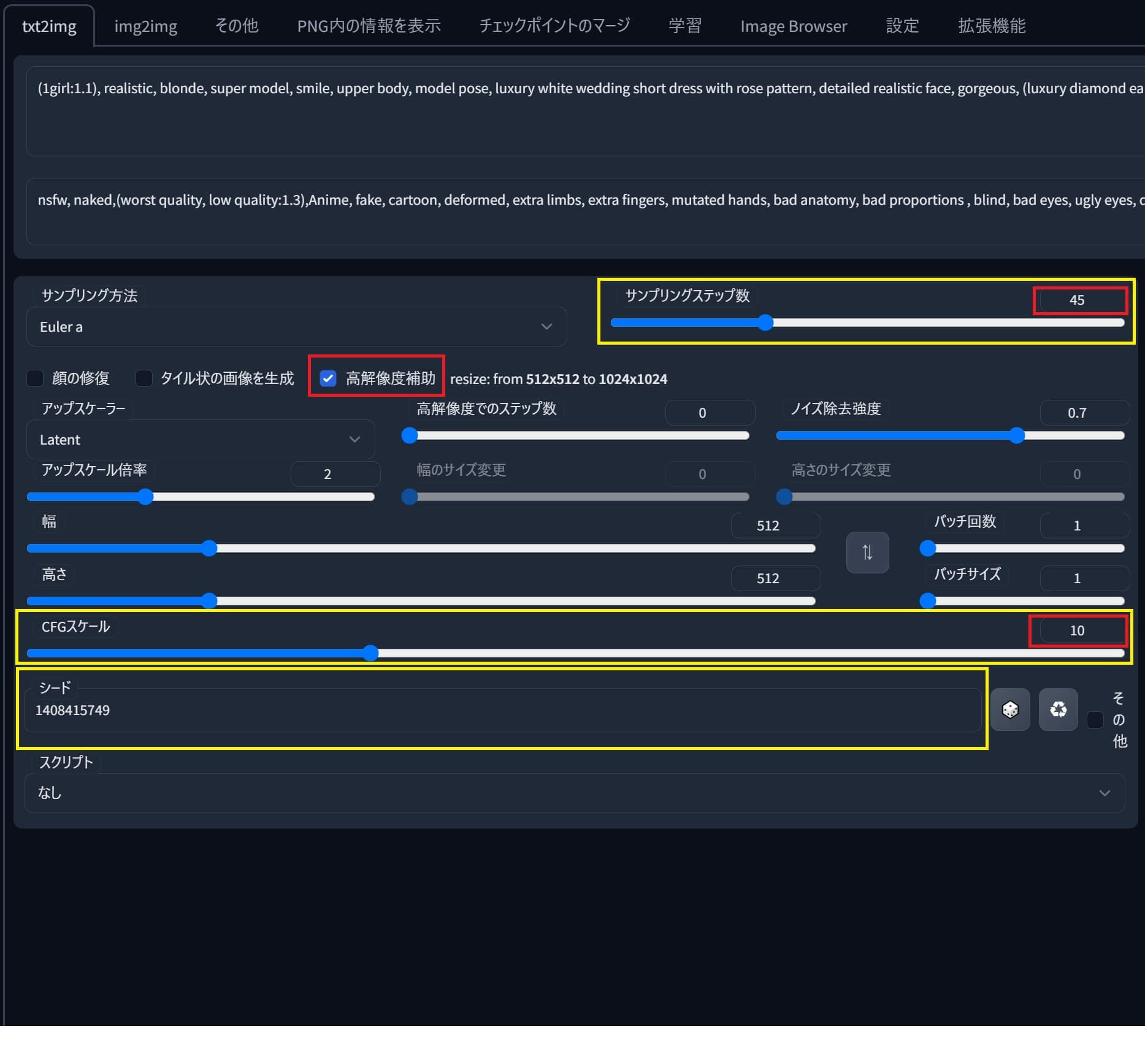
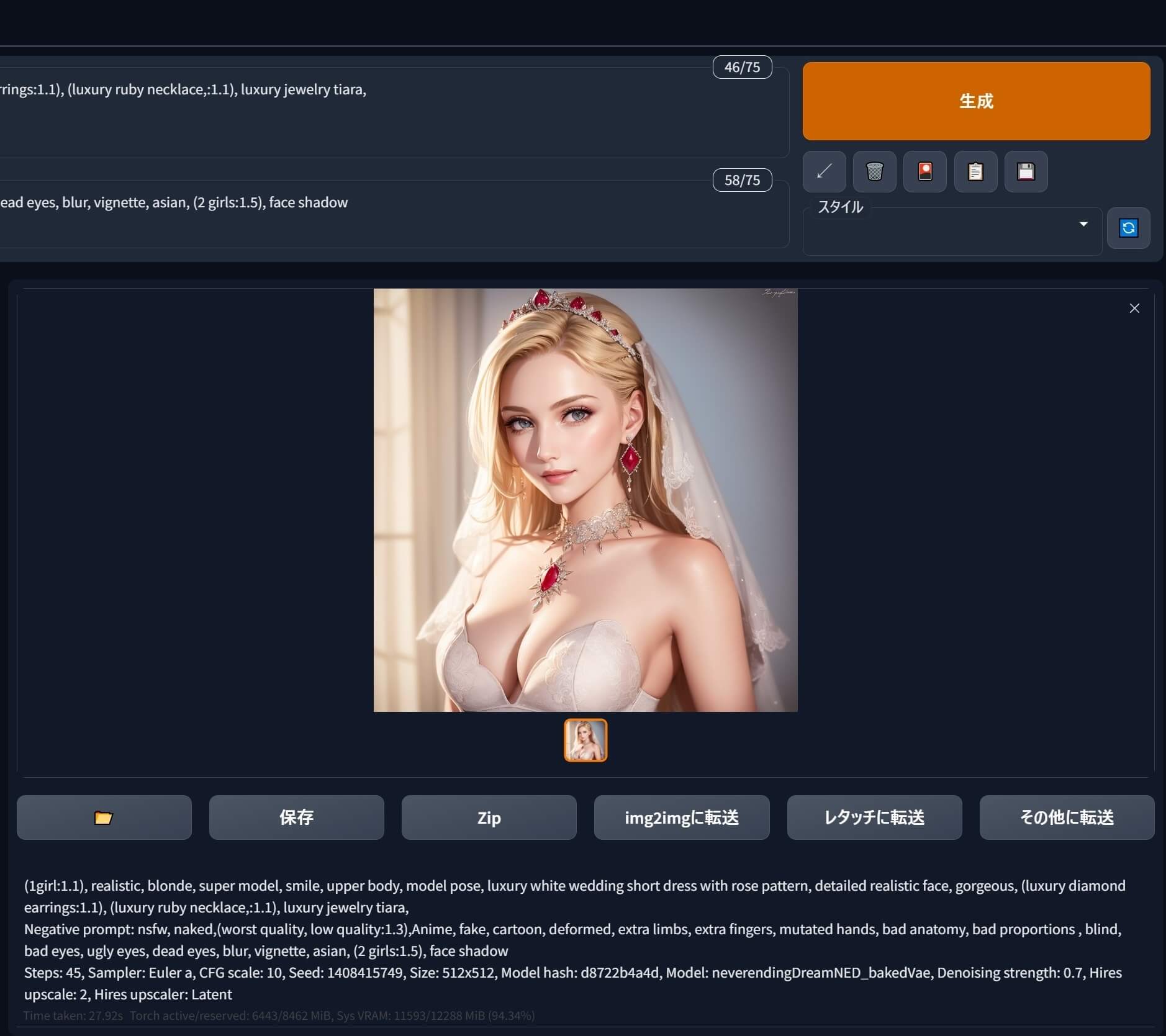
③そして、最終的に「生成」して出来上がった高画質の「お気に入り画像」がコチラ♪↓
| ★高画質した「お気に入り画像」 | 「X/Y/Z Plot」で生成した「お気に入り画像」を同じシード値で高画質化して再生成 |
 |
 |
| 拡張機能「LLuL」の重み(Weight)の違いによる画像品質の変化(★お気に入り画像) | |
 |
|
| ★「LLuL」Weight 0.4 | ★★「LLuL」Weight 0.5 |
 |
 |
おすすめ拡張機能『LLuL』ローカル潜在アップスケーラーのインストール方法&実用的な使い方
拡張機能『LLuL – Local Latent upscaLer』ローカル潜在アップスケーラーとは?
おすすめ拡張機能『LLuL』ローカル潜在アップスケーラーのインストール方法
①「拡張機能」タブを選択後 ➡ ②「拡張機能リスト」を選択。
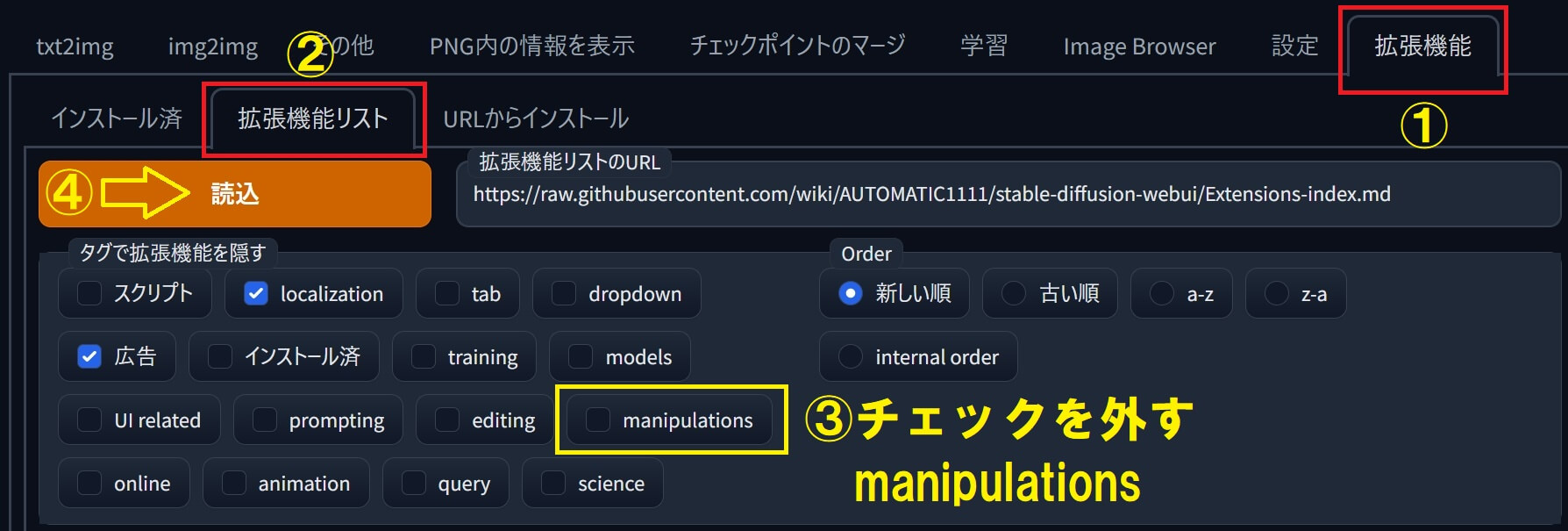
③「manipulation」の✅チェックを外し ➡ ④「読込」を押すとリストが表示されます。↑
⑤リストの中から「LLuL」を選び、右側の「インストール」を押します。↓
 |
|
⑥「インストール済」タブを選択して「適用して再起動」を押す。

⑦再起動後に「LLuL」のメニューが追加され表示されたらインストール完了。
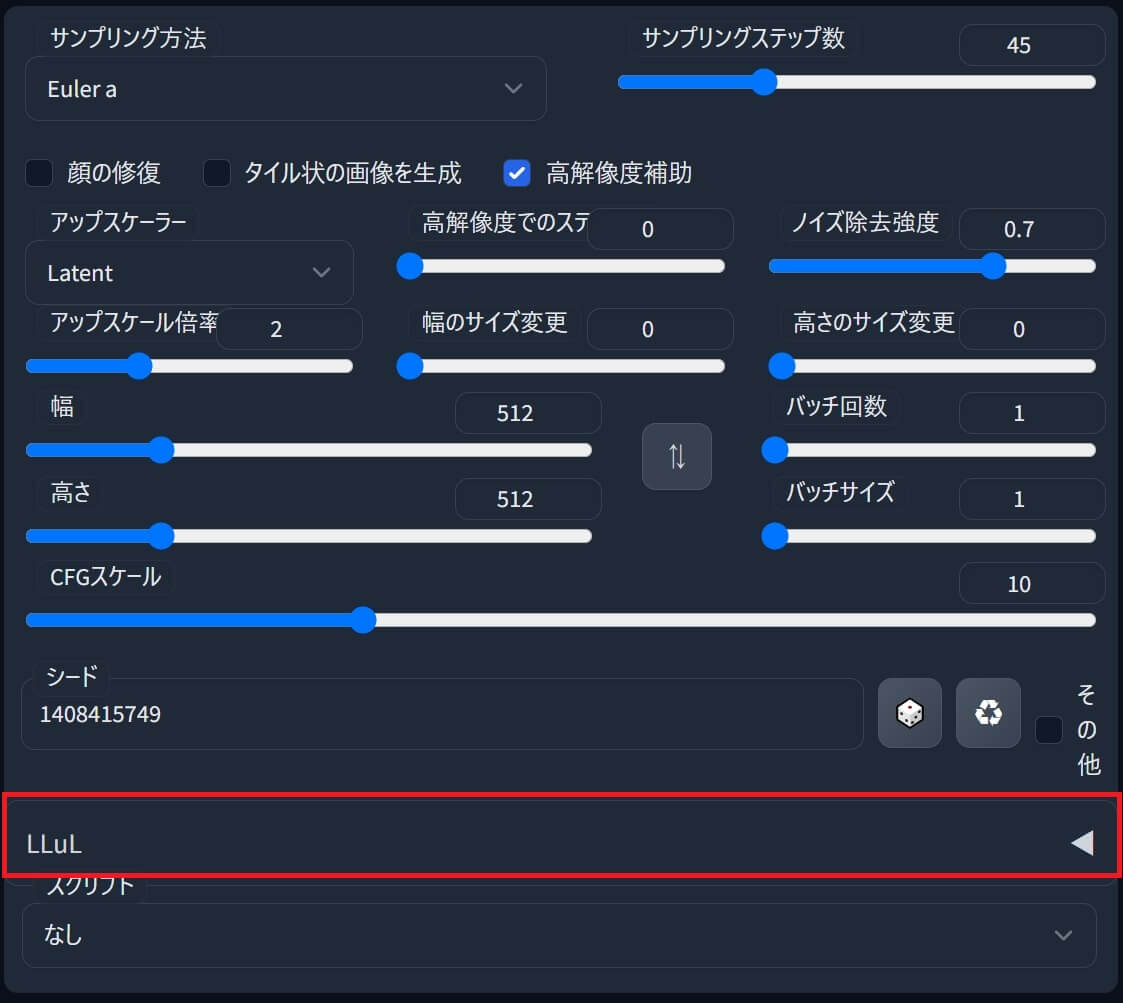
拡張機能『LLuL』ローカル潜在アップスケーラーの使い方
①「LLuL」をクリックしてメニューを開き「有効」に✅チェックを入れます。
②「重さ」(Weight)を、最大0.5位までで調整し、ネズミ色の四角(■)をマウスで移動します。
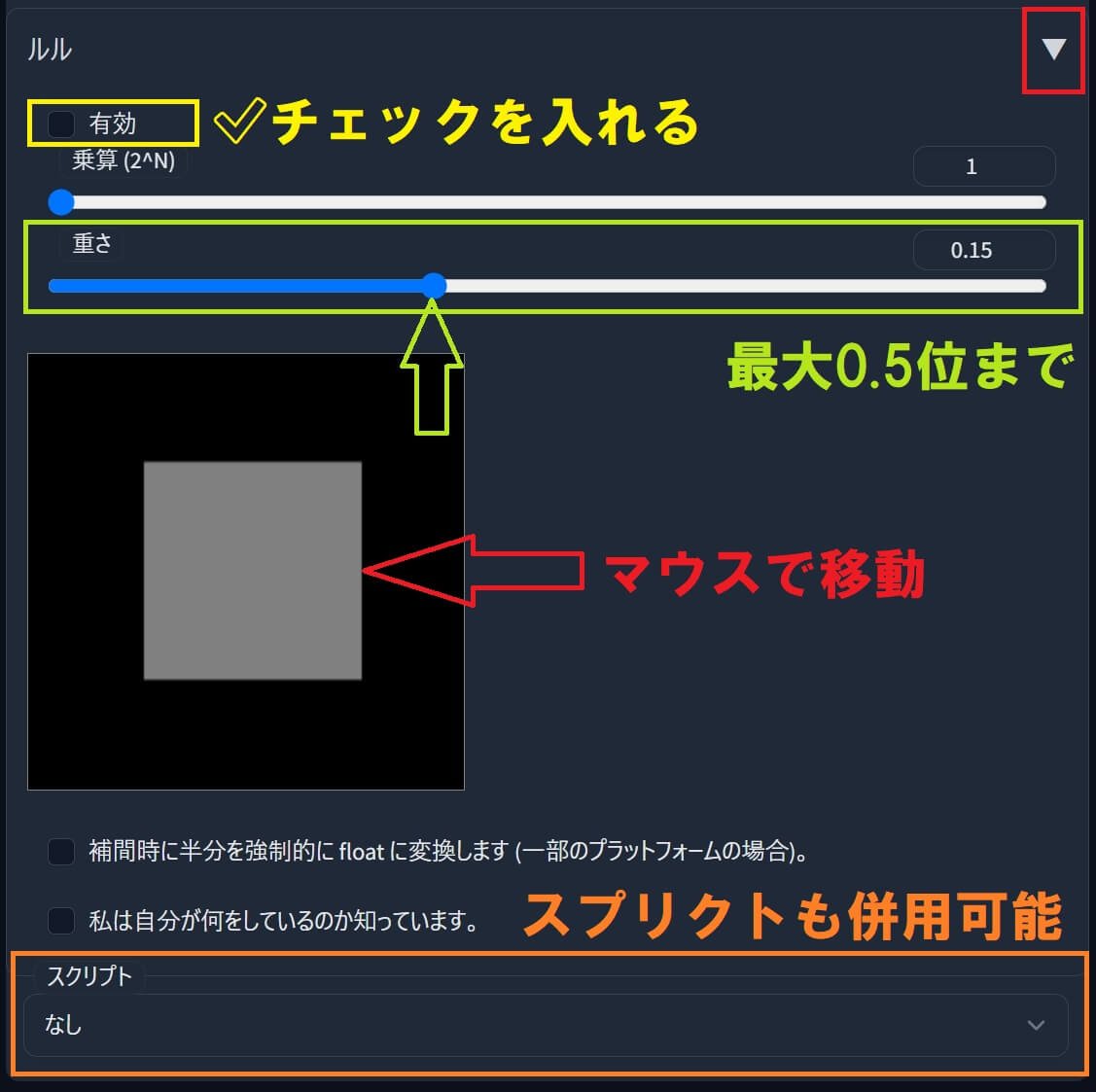
③「LLuL」メニューを閉じて最後に「生成」ボタンを押すと、画像が出力されます。
【3分で語る】Stable diffusion web UI 拡張機能 LLuL&XYZ プロットの実用的な使い方😊画像の生成精度を更に高める方法💕YouTube ![]()
アップスケーラー「4x-UltraSharp」の導入方法

●ファイルのインストール先は、以下のフォルダ内。
ENSDの意味と使い方。ENSD:31137とは?ENSDの場所はどこにある?
「ENSD」とは?
●「ENSD」は「Eta noise seed delta(イータ・ノイズ・シード・デルタ)」の略語です。
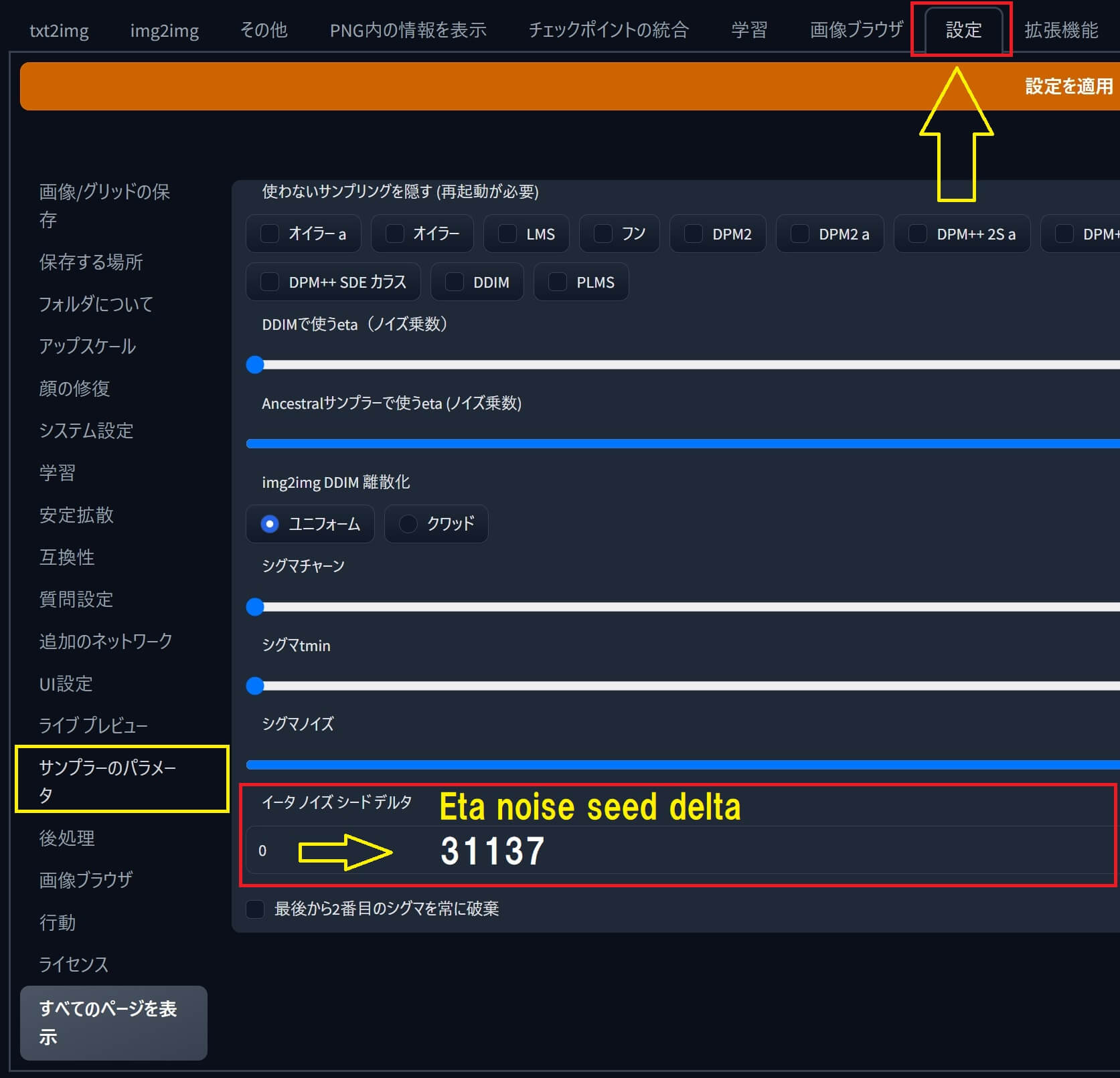
「ENSD」の場所はどこにある?(Stable diffusion web UI)
●「ENSD」のある場所は『Stable diffusion web UI』のブラウザ画面で「設定」➡「サンプラーのパラメータ」を開くと「Eta noise seed delta」が下の方に有ります。
「ENSD」の意味と使い方
●「Eta noise seed delta(ENSD)」の初期値(デフォルト値)はゼロ「0」です。
●「ENSD:31337」にする場合は値を「0」から ➡「31337」に変更し、「設定を適用」を押してから「UIの再読み込み」ボタンを押せば内容が更新されます。
問題解決の為の忘備録メモ
Loraが使えない・効かない・使えなくなった。
●問題:拡張機能「a1111-sd-webui-locon」がインストールされていると「Lora」が使えなくなる事例が発生。↓↓
●対策:locon をオフにする、又は削除する。その場合、端末と起動コマンドプロンプト、両方の再起動が必要です。
 この拡張機能(locon)は基本的に非推奨であり、正式な更新はまったくありません。
この拡張機能(locon)は基本的に非推奨であり、正式な更新はまったくありません。代わりにa1111-sd-webui-lycoris を使用することを検討してください 。
イメージブラウザ(Image Browser)の画像が表示されない
●問題:拡張機能「イメージブラウザ」をアップデートすると画像の読込みエラーが発生する。
●対策:以下記事参照。↓↓

『Stable diffusion web UI』本体をバージョンアップ(アップデート)したら拡張機能などが使えくなった。不具合やバグが発生した。
●『Stable diffusion web UI』本体の環境を、フォルダ名を変えて2環境(2つ)インストールしておくと、いざという時に役立ちます。
●筆者おすすめの提案は「ZIPファイル版」と「git clone インストール版」両方の運用。
もしくは「git clone インストール版」を新旧、バックアップの為に2種類運用する。
LORAモデルのサムネイル画像が一部表示されず読み込まれなくなった
●現在選択されているメインのモデル(.ckp)を、別のモデルに切り替えると直る場合が有ります。
No Image data blocks found.(画像データ ブロックが見つかりません)
「SD-WEB UI」のコマンドラインに「No Image data blocks found.」と表示された場合、以下のフォルダ内に不要なファイルが存在する可能性が有ります。
●具体的には「Texutual Inversion」「Hypernetworks」内の、サムネイル画像のファイル名が、「モデル名.preview.png」の文字が「有り&無し」で2種類(2枚)フォルダ内に存在している。
絵画のジャンル(全20種類)画風・作風・スタイル
①オイルペインティング(油絵)- Oil Painting
②アクリルペインティング – Acrylic Painting
③水彩画 – Watercolor Painting
④パステル画 – Pastel Painting
⑤インク画 – Ink Painting
⑥エッチング – Etching
⑦リトグラフ – Lithography
⑧ポートレート画 – Portrait Painting
⑨静物画 – Still Life Painting
⑩風景画 – Landscape Painting
⑪抽象画 – Abstract Painting
⑫キャンバスによるコラージュ – Canvas Collage
⑬モザイクアート – Mosaic Art
⑭デジタルアート – Digital Art
⑮立体絵画 – Sculptural Painting
⑯フレスコ画 – Fresco Painting
⑰ミニチュア絵画 – Miniature Painting
⑱ポップアート – Pop Art
⑲レアリズム – Realism
⑳モノクローム絵画 – Monochromatic Painting
結論:まとめ
AI画像生成ツールを活用する事で出来る事。メリット
創造性の拡張
時間と労力の節約
リソースの多様化
ブランディングとマーケティング活用
様々なバリエーションの画像を作成して実験・テスト
プロジェクトの柔軟性
まとめ
今回は『Stable diffusion web UI』を使用可能にする為に、私が実際に作業したインストール手順、及び基本的な使い方、各ツールのインストール方法、操作パネル(UI)の概要、LoRaの使い方などを、解説&ご紹介しました。
●今回記事をまとめて感じた事は『Stable diffusion web UI』は人間のように「曖昧」「いい加減」「適当」「中途半端」な要素を(良い意味で)数多く含める事が可能、だと言う事。
●余談ですが「適当」の意味をネット辞書で調べると「ちょうどよく合う事」「ふさわしい事」「ある条件・目的・要求などに、うまく当てはまる事」などと出てきます。
●さて、本記事を書いた時点の筆者のPC環境は以下の通り。↓
●「画像生成AI(人工知能)ツール」は、次世代に向けて急速な進化が期待される新たな分野です。
他のAIツール『ChatGPT』等と組み合わせ併用したり、PCゲームと組み合わせたり、様々な分野でAI活用・発展・進化は加速していくでしょう。
